
In a small series, we will describe the approach in our projects along our data value chain. The series of articles consists of three parts: "Data Purpose and Data Visualization," "Data Transformation and Data Analysis," and "Data Collection". zipcon consulting, one of the leading consulting firms in the print and media industry in the German-speaking world, asked us to outline the approach for a medium-sized print shop from the perspective of data experts.
In the first part of this series, we defined the data value chain and described the first steps on the way to data visualization and data analysis. As an example, we focused on a fictitious print shop with 100 employees. The print shop wants to build a dashboard and asks itself the question:
In what quantities were print products such as brochures, flyers or postcards produced in Germany in the past five years (2016 - 2021)?
In the second part of our series, we will look at the next steps in the data value chain: Data Hub and Data Science.
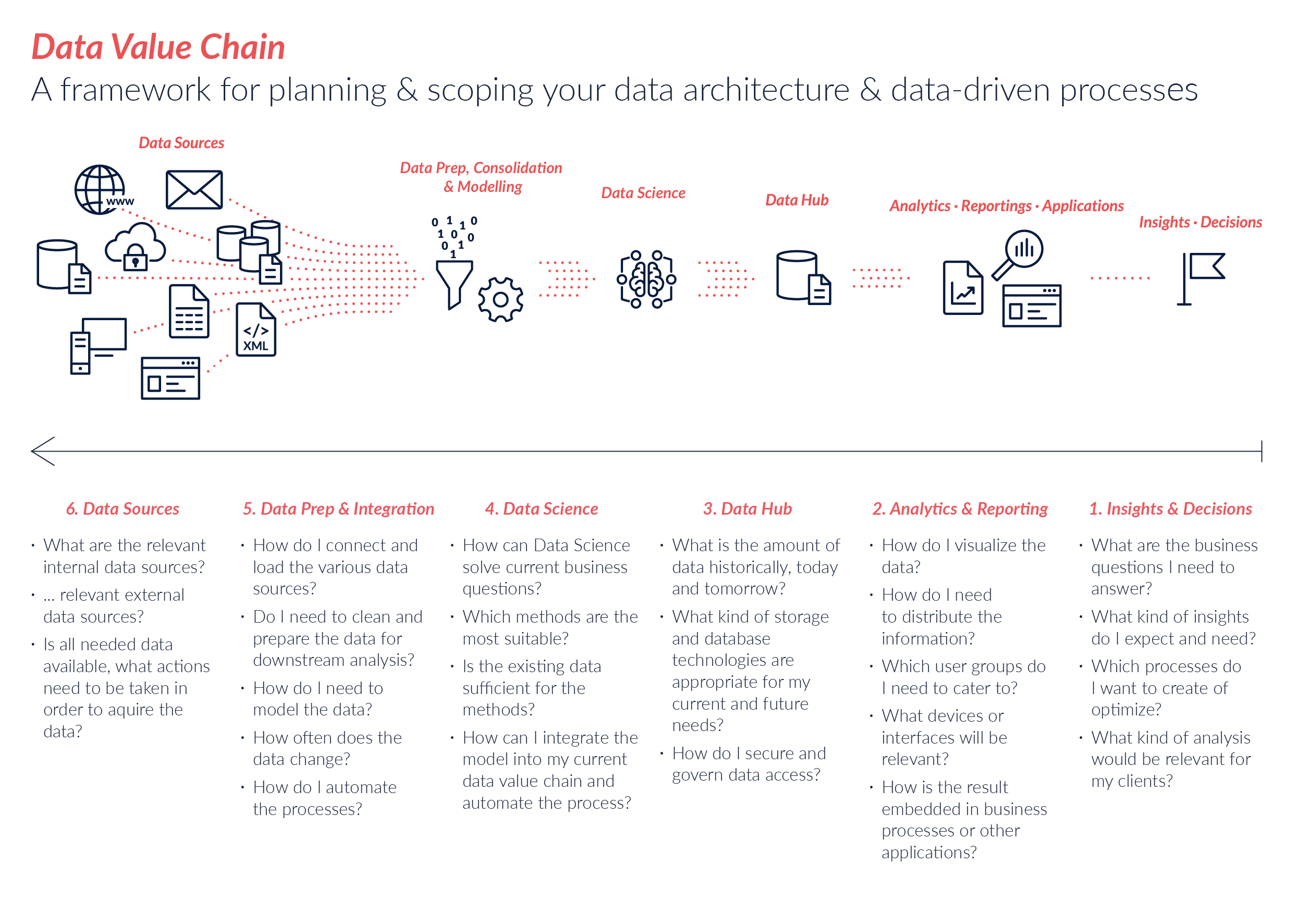
Data Hub
In order to perform data analysis, you have to think about the underlying data in advance: How much data do I need? What kind of storage technologies are suitable for my current needs? How do I secure and regulate data access?
Data volume
Data volumes play an important role in the project because the goal is to build a sustainable dashboard or reporting system that can meet user expectations.
Determining when a data set is considered large or small is relative. There is no general definition for this. IT consultancies know what capacities different technologies bring and what volumes of data can be processed. The goal of the project work is always that the user has a workable and well-functioning solution at the end.
Data base technologies
Data must be stored on a database in order to have access to it at all. Based on the information about the amount of data, it is decided what kind of storage and database technologies are suitable for the project. We at M2, for example, use the solutions of AWS RDS (Amazon Relational Database Service) and Exasol databases.
Amazon RDS is a Web service that simplifies setting up, running and scaling a relational database in the AWS cloud. This service provides cost-effective and customizable capacity for an industry-standard relational database and management of common database tasks.
Exasol is a parallelized relational database management system (RDBMS) running on a cluster of standard computer hardware servers. Following the SPMD model, the same code is executed simultaneously on each node. This makes Exasol one of the fastest databases in the world.
Each project should be considered individually. In order to choose a suitable solution for data storage and processing, it is worthwhile to seek expert advice.
However, for our example, other data storage solutions are used. In this case, we are dealing with data from 2016 – 2021, so it is a manageable amount of data, even if we will work exclusively with raw data.
As a solution for storing the data in our example, a standard database like MySQL is suitable. MySQL is an open source SQL database management system. SQL stands for ‘Structured Query Language’ and is the most common standardized language for accessing databases. This database (like any other) must be installed on a separate server or on your own computer like the web server.
It is recommended to store the data centrally in a database so that the entire IT department has access to it. This solution has other advantages such as transparency, customization options, and provision to other participating departments. The databases should be set up and managed by database administrators.
The data from our example can also be stored locally in a text file. This type of data storage is simple and fast, but it does have disadvantages. The data in this form is not visible to data managers or IT departments. This leads to the difficulties in managing the data. If this data contains personal information, it must be ensured that the data is handled in accordance with the applicable legislation.
How do I control and secure data access?
Data access is a term from computer technology and describes the physical process of reading certain data and information on storage devices. These can be logical drives or databases.
Data access should be protected because sensitive customer data must be protected first and foremost. Company secrets or personal customer addresses must never be made available to third parties via the Internet.
The most common way to protect access to data is to use VPN services. VPN stands for Virtual Private Network. VPN includes various procedures, techniques and protocols for virtual connections, encrypted communication, secure data exchange and private transmissions. In essence, VPN services usually ensure the aspects of authenticity, encryption and integrity. Authenticity in this context means the authorization of users, while encryption refers to communication and data exchange. Integrity is also intended to make it clear that third parties cannot modify the data. Depending on the use case, various techniques and procedures are used to cover all aspects.
Data Science
Just like Data Analysis, the subject area of Data Science is very extensive. Data Science is an interdisciplinary field of science that provides scientifically sound methods, processes, algorithms and systems for extracting insights, patterns and conclusions from both structured and unstructured data.
We use Data Science in projects when we are dealing with large and unmanageable amounts of data. Machine Learning, Regression Analysis or Algorithms help us to better understand the data. We use Python and AWS to perform these methods. At M2, we have a team of Data Scientists who deal with day-to-day questions in this field on a permanent basis.
However, the application of such methods in our example is redundant. That is why we will not look at this area in more detail.
Find the thrid and last part of this series here – you will learn more about the next steps Data Prep & Integration and Data Sources on our data value chain.
info@m2dot.com · M2@Facebook · M2@Twitter · M2@LinkedIn · M2@Instagram