

In einer kleinen Serie wird die Vorgehensweise in unseren Projekten entlang unserer Datenwertschöpfungskette geschildert. Die Artikelreihe besteht aus den drei Teilen „Datenzweck und Datenvisualisierung“, „Datentransformation und Datenanalyse“ sowie „Datensammlung“. zipcon consulting, eines der führenden Beratungsunternehmen in der Druck- und Medienbranche im deutschsprachigen Raum, hat uns gebeten, aus der Sicht von Datenexperten das Vorgehen für eine mittelständische Druckerei zu skizzieren.
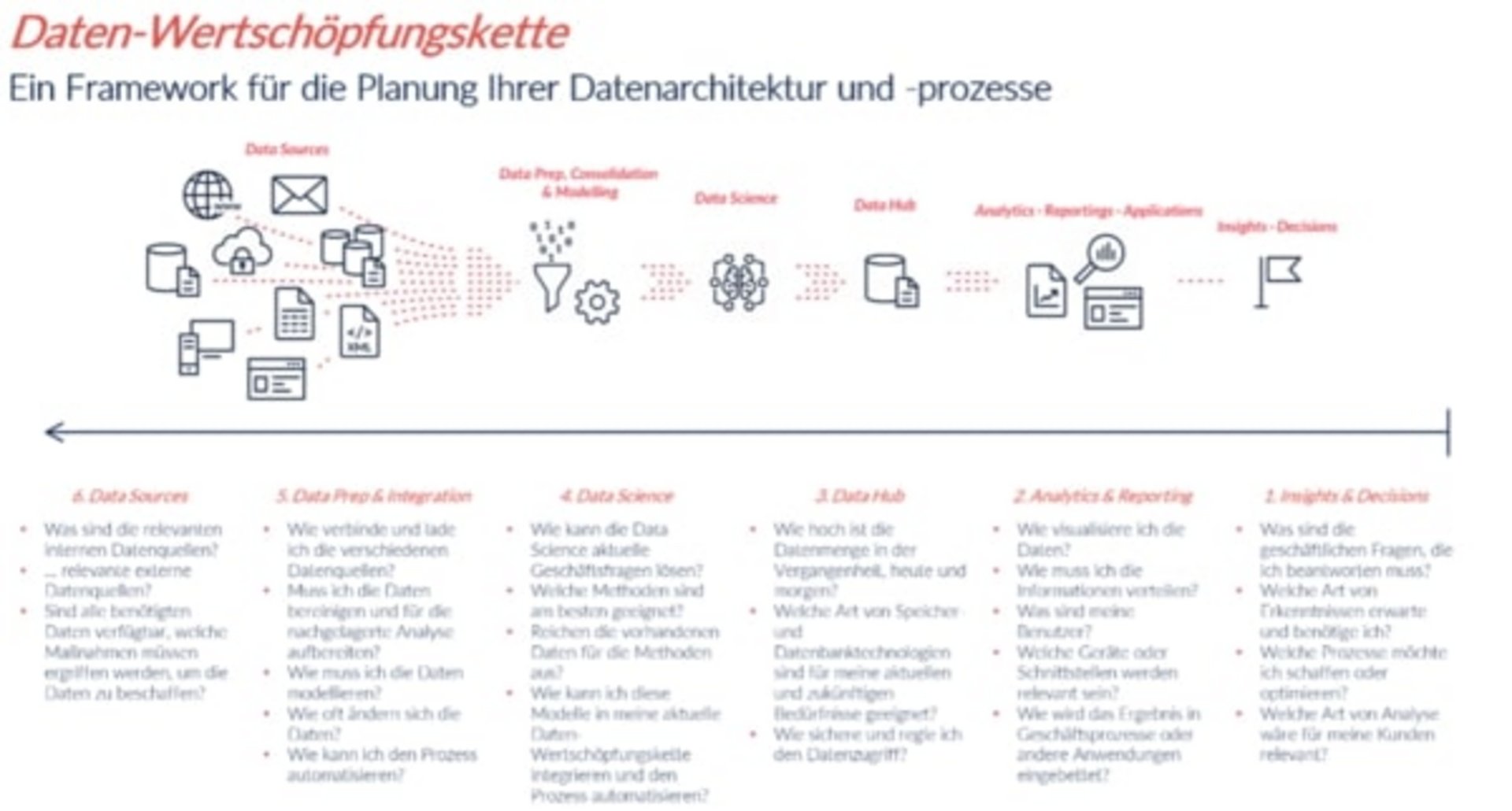
Im ersten Teil dieser Reihe haben wir die Datenwertschöpfungskette definiert und die ersten Schritte auf dem Weg zur Datenvisualisierung und Datenanalyse beschrieben. Als Beispiel haben wir uns auf eine fiktive Druckerei mit 100 Mitarbeiter*innen fokussiert. Die Druckerei möchte ein Dashboard bauen und stellt sich dabei die Frage:
In welcher Stückzahl wurden Druckprodukte wie Broschüren, Flyer oder Postkarten in den vergangenen fünf Jahren (2016 - 2021) in Deutschland produziert?
Im zweiten Teil unserer Reihe geht es um die weiteren Schritte in der Datenwertschöpfungskette: Data Hub und Data Science.
Data Hub
Um Datenanalysen durchzuführen, muss man sich im Vorfeld Gedanken über die Daten an sich machen: Wie hoch ist die Datenmenge? Welche Art von Speichertechnologien sind für meine aktuellen Bedürfnisse geeignet? Wie sichere und regle ich den Datenzugriff?
Datenmengen
Datenmengen spielen im Projekt eine wichtige Rolle, denn es geht darum, ein nachhaltiges Dashboard oder Berichtswesen aufzubauen, welches die Erwartungen der Nutzer erfüllen kann.
Wann eine Datenmenge als groß oder klein bezeichnet wird, ist relativ. Dazu gibt es kleine allgemeine Definition. Als IT-Beratungsunternehmen wissen wir natürlich, welche Kapazitäten die unterschiedlichen Technologien mit sich bringen und welche Datenmengen verarbeitet werden können. Ziel der Projektarbeit ist immer, dass der User am Ende eine arbeitsfähige und gut funktionierende Lösung hat.
Datenbanktechnologien
Daten müssen auf einer Datenbank gespeichert werden, um auf sie überhaupt Zugriff zu haben. Anhand der Information über die Datenmenge wird entschieden, welche Art von Speicher und Datenbanktechnologien sind für das Projekt geeignet. Wir bei M2, nutzen beispielsweise die Lösungen von AWS RDS (Amazon Relational Database Service) und Exasol Datenbanken.
Amazon RDS ist ein Webservice, der das Einrichten, Betreiben und Skalieren einer relationalen Datenbank in der AWS Cloud vereinfacht. Dieser Service bietet kostengünstige und anpassbare Kapazitäten für eine den Branchenstandards entsprechende relationale Datenbank sowie die Verwaltung gängiger Datenbankaufgaben.
Exasol ist ein parallelisiertes, relationales Datenbankmanagementsystem (RDBMS), das auf einem Cluster von Standard-Computerhardware-Servern läuft. Nach dem SPMD-Modell wird auf jedem Knoten der gleiche Code gleichzeitig ausgeführt. Das macht Exasol zu einer der schnellsten Datenbanken der Welt.
Jedes Projekt soll individuell betrachtet werden. Um eine passende Lösung für Datenspeicherung und -verarbeitung auswählen zu können, soll man im besten Fall einen Expertenrat zu holen.
Für unser Beispiel jedoch kommen andere Lösungen zur Datenspeicherung zum Einsatz. In unserem Fall handelt es sich um Daten der Jahre 2016 – 2021. Es ist also eine überschaubare Datenmenge, selbst dann, wenn wir ausschließlich mit Rohdaten arbeiten werden.
Als Lösung für die Speicherung der Daten in unserem Beispiel eignet sich eine Standarddatenbank wie MySQL. MySQL ist ein quelloffenes SQL-Datenbank-Managementsystem. SQL steht für ‚Structured Query Language‘ (strukturierte Abfragesprache) und ist die gebräuchlichste standardisierte Sprache für den Zugriff auf Datenbanken. Diese Datenbank (wie jede andere) muss auf einem separaten Server oder auf dem eigenen Rechner wie der Webserver installiert werden.
Es ist zu empfehlen, die Daten zentral in einer Datenbank abzulegen, so dass die gesamte IT-Abteilung Zugriff darauf hat. Diese Lösung hat weitere Vorteile, wie Transparenz, Anpassungsmöglichkeiten und Bereitstellung an weitere, beteiligte Abteilungen. Die Einrichtung der Datenbanken sollte durch Datenbank-Administratoren erfolgen und von ihnen verwaltet werden.
Die Daten aus unserem Beispiel können ebenso lokal in einer Textdatei gespeichert werden. Diese Art der Datenspeicherung ist einfach und schnell, hat aber durchaus Nachteile. Die Daten sind in dieser Form nicht für Datenmanager oder IT-Abteilungen sichtbar. Das führt zu den Schwierigkeiten beim Management der Daten. Falls diese Daten personenbezogene Informationen beinhalten, muss sichergestellt werden, dass die Daten entsprechend der gültigen Gesetzgebung behandelt werden.
Wie sichere und regle ich den Datenzugriff?
"Datenzugriff ist ein Begriff aus der Computertechnik und beschreibt den physikalischen Vorgang des Lesens bestimmter Daten und Informationen auf Speichergeräten. Dabei können die logischen Laufwerke oder Datenbanken sein." https://de.wikipedia.org/wiki/Datenzugriff
Der Datenzugriff sollte geschützt werden, weil wir die sensiblen Kundendaten in erste Linie schützen müssen. Firmengeheimnisse oder persönliche Kundenadressen dürfen auf keinen Fall über das Internet für Dritte zugänglich gemacht werden.
Die gängigste Methode, den Zugriff auf Daten zu schützen, ist die Nutzung von VPN Services. VPN steht für Virtual Private Network. VPN beinhaltet unterschiedliche Verfahren, Techniken und Protokolle für virtuelle Verbindungen, verschlüsselte Kommunikation, sicheren Datenaustausch und private Übertragungen bezeichnet und zusammengefasst. Im Wesentlichen stellen VPN Services dabei meist die Aspekte Authentizität, Verschlüsselung und Integrität sicher. Authentizität bedeutet in diesem Zusammenhang die Autorisierung von Nutzern, während sich die Verschlüsselung auf die Kommunikation und den Datenaustausch bezieht. Integrität soll zudem verdeutlichen, dass Dritte die Daten nicht verändern können. Je nach Anwendungsfall kommen verschiedene Techniken und Verfahren zum Einsatz, die nicht alle drei Aspekte abdecken.
Data Science
Genau wie Data Analysis ist das Themenfeld Data Science sehr umfangreich. Data Science ist ein interdisziplinäres Wissenschaftsfeld, welches wissenschaftlich fundierte Methoden, Prozesse, Algorithmen und Systeme zur Extraktion von Erkenntnissen, Mustern und Schlüssen sowohl aus strukturierten als auch unstrukturierten Daten ermöglicht.
Wir verwenden Data Science in Projekten, wenn wir es mit großen und unüberschaubaren Datenmengen zu tun haben. Machine Learning, Regressions Analyse oder Algorithmen helfen uns dabei, die Daten besser zu verstehen. Für die Durchführung dieser Methoden verwenden wir Python und AWS. Bei M2 haben wir ein Team von Data Scientists, die sich mit den alltäglichen Fragen auf diesem Gebiet dauerhaft beschäftigen.
Die Anwendung solcher Methoden in unserem Beispiel ist jedoch überflüssig. Deswegen werden wir diesen Bereich nicht näher betrachten.
Den dritten und letzten Teil lesen Sie hier– erfahren Sie dann mehr zu den nächsten Schritten Data Prep & Integration und Data Sources auf unserer Datenwertschöpfungskette.
Sie haben Fragen zu diesem Artikel oder zu M2? Dann kommen Sie jederzeit gern auf uns zu. Wir freuen uns auf den Austausch mit Ihnen.
Ihr M2 Team
Telefon: +49 (0)30 20 89 87 010
info@m2dot.com · M2@Facebook · M2@Twitter · M2@LinkedIn · M2@Instagram
Ähnliche News

- OTC
- ThoughtSpot
- M2
- Alteryx
- Tableau
- Events
M2 NewsBlog: 14.02.2023
M2 Breakfast | Alter.Next | Customer Stories | Managed Services | OTC
Weiterlesen
- Webinar
- Training
- M2
- Tableau
M2 NewsBlog: 10.11.2022
Tableau Test Drive | Data Science Training | Mail Tool | M2 Team im neuen Look
Weiterlesen
- Exasol
- AWS
- Webinar
- Training
- M2
- Alteryx
- Tableau
M2 NewsBlog: 17.10.2022
Alteryx Classroom Training | Tableau like a Pro | Nosta Group | eCommerce Connector
Weiterlesen
- Exasol
- Webinar
- Training
- M2
- Tableau
M2 NewsBlog: 21.09.2022
13 Jahre M2 | Alteryx Inspire | Exasol & Labor Berlin | Videodreh | Zipcon
Weiterlesen


- Webinar
- Training
- M2
- Alteryx
- Events
- Tableau
M2 NewsBlog: 02.09.2022
M2 Events & News | Schulungen | Webinare | Tableau | Alteryx | AWS
Weiterlesen
- Webinar
- Training
- M2
- Alteryx
- Tableau
- Events
M2 NewsBlog: 19.08.2022
M2 Events & News | Schulungen | Webinare | Tableau | Alteryx | AWS
Weiterlesen

- M2
- Tableau
M2 - Ihr Partner für Datenvisualisierung und Analyse
Wir helfen Ihnen, das Datenpotential Ihres Unternehmens auszuschöpfen
Weiterlesen