

von Dilyana Bossenz, Business Intelligence Consultant
Relationships: Tableaus neues Datenmodell im Überblick
In der Tableau Version 2020.2 wurde ein neues Datenmodell mit Relationships eingeführt, welches unsere Arbeit mit Daten erleichtert, aber ein neues Denken erfordert. In diesem Blog-Artikel haben wir kurz die relevantesten Punkte für Sie zusammengefasst, damit Sie wissen, was Sie beim neuen Datenmodell beachten müssen. Den verwendeten Datensatz zu diesem Blogartikel finden Sie hier.
Was ist das neue Datenmodell?
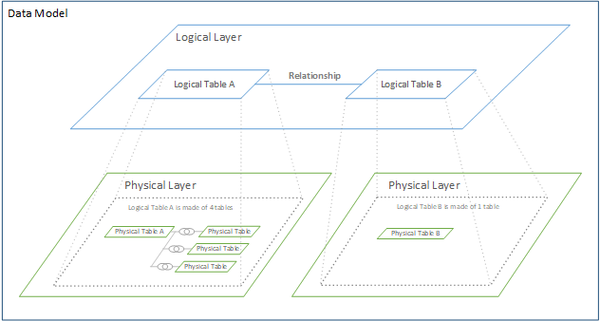
Das neue Datenmodell beinhaltet logische und physische Ebenen, was in Tableau auf der Seite „Datenquelle“ sichtbar ist.
Die physische Ebene ist bereits aus Tableau 2020.1 und niedrigeren Versionen bekannt. Auf ihr werden bei Bedarf mehrere Tabellen durch Data Joins oder Unions zu einer physischen Tabelle zusammengeführt.
Die neue logische Ebene bildet die Beziehungen, oder „Relationships“, zwischen diesen physischen Tabellen.
Was sind Relationships?
Mit Relationships erstellen Sie eine Beziehung zwischen mehreren Tabellen, indem Sie definieren, welche Spalten (Felder) diese Tabellen gemeinsam haben.
Mit Relationships bilden Sie eine flexible Datenquelle mit mehreren separaten Tabellen. Hier liegt der wesentliche Unterschied zu Data Joins oder Data Blending, wobei mehrere Tabellen in eine Tabelle fest zusammengeführt werden. Dadurch, dass Relationship die separaten Tabellen beibehält, kann Tableau leichter erkennen, welches Feld aus welcher Tabelle kommt. Das bedeutet, dass jedes Feld seinen Kontext oder seine Detailgenauigkeit beibehält. Darüber hinaus wird die Granularität der Daten jedes Mal neu verarbeitet, je nachdem, welche Dimensionen und Kennzahlen in einem Chart benutzt werden. Wir müssen uns also keine Gedanken mehr im Voraus über die Granularität der Daten machen, wie es bei Data Joins oder Data Blendings der Fall ist. Es passiert automatisch, sobald wir ein Chart erstellen.
Was ist zu beachten?
Datenquelle
Wenn Sie Tableau 2020.2 (und höher) öffnen und zwei Tabellen in den Arbeitsbereich ziehen, wird automatisch eine Beziehung zwischen den Tabellen erstellt. Wo es möglich ist geschieht dies über eine gemeinsame Spalte (Key) .
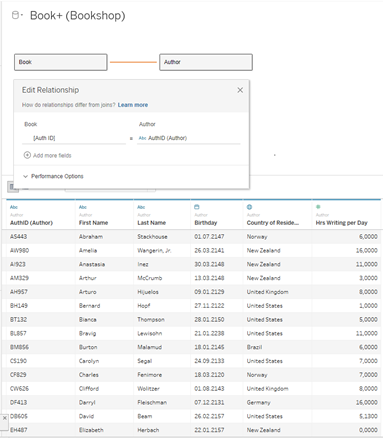

Im unteren Bereich sehen Sie die Tabelle, die gerade im Arbeitsbereich ausgewählt ist. Es wird nicht mehr eine Tabelle angezeigt, die aus mehreren Tabellen besteht.
Dimensionen/Kennzahlen
Im Arbeitsbereich eines Arbeitsblattes (Worksheet) gibt es ebenfalls Änderungen. Auf der linken Seite gibt es in diesem Fall drei Blöcke:
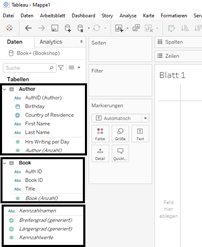
In dem Block oben und in der Mitte sehen wir unsere beiden Tabellen mit den Dimensionen und Kennzahlen. Die Dimensionen und Kennzahlen sind durch eine Linie getrennt. In dem unteren Block sehen wir Dimensionen und Kennzahlen, die automatisch von Tableau generiert werden. Dazu zählen: Kennzahlnamen und Kennzahlwerte, sowie Längen- und Breitengrad (generiert). Erstellte Sets und Gruppen werden automatisch bei jenen Tabellen erscheinen, auf denen sie basieren.
Anzahl der Datensätze
Die Kennzahl „Anzahl der Datensätze“ wird nun anders dargestellt. Jede Tabelle hat ihre eigene Anzahl der Datensätze, die anders benannt ist: Tabellenname(Anzahl).
Der Grund für die Trennung zwischen den Tabellen ist, dass die ursprüngliche Idee mit der gemeinsamen Kennzahl „Anzahl der Datensätze“ nicht mehr funktioniert, denn: Mit Relationships betrachten wir jede Tabelle separat. Jede Tabelle hat ihre eigene Granularität und Detailgenauigkeit. Somit hat auch jede Tabelle ihre eigene Kennzahl Tabellenname(Anzahl).
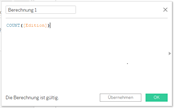
Zudem ist diese Kennzahl jetzt aggregiert. Das sehen wir, wenn wir ein berechnetes Feld mit dieser Kennzahl erstellen:
Wenn Sie diese Kennzahl in ihrer Datenvisualisierung benutzt haben und sie in einer früheren Tableau Versionen erstellt haben, stellt dies kein Problem dar. Die Kennzahl wird beibehalten. Hier sehen wir das in einem Beispiel: Ich habe eine Arbeitsmappe in Tableau 2020.1 erstellt, wo ich die Kennzahl „Anzahl der Datensätze“ benutzt habe.
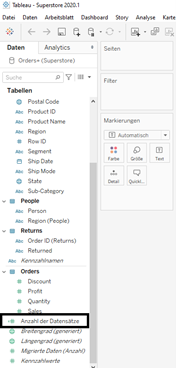
Berechnete Felder
Das Verhalten der berechneten Felder ist ebenfalls zu beachten.
Wenn eine Dimension als berechnetes Feld mit Dimensionen und Kennzahlen aus Tabelle A erstellt wird, wird sie in der Tabelle A unter Dimensionen erscheinen
Beispiel: Tabelle Author
Feldname: Name
[First Name]+" "+[Last Name]
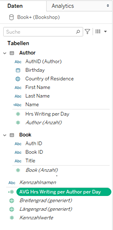
Wenn eine Kennzahl als berechnetes Feld mit Dimensionen und Kennzahlen aus Tabelle A erstellt wird, wird sie im „Neutralen Block“ unten erscheinen
Beispiel: Tabelle Author
Feldname: AVG Hrs Writing per Author per Day
sum([Hrs Writing per Day])/COUNT([Author])
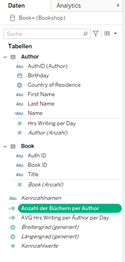
Wenn eine Kennzahl/Dimension als berechnetes Feld mit Dimensionen und Kennzahlen aus mehreren Tabellen erstellt wird, wird sie ebenfalls im „Neutralen Block“ unten erscheinen
Beispiel: Tabelle Author und Book
Feldname: Anzahl der Bücher per Author
COUNT([Book])/COUNT([Author])
Alle Datensätze auf einen Blick
Vor dem Update auf Relationships musste im Voraus überlegt werden, welcher Join Typ für die Kombination vonDimensionen und Kennzahlen aus mehreren Tabellen der Richtige war. Bei einigen Joins konnten Daten verloren . Bei Relationships gibt es diese Problematik nicht. Es werden alle Daten angezeigt.Keine Information geht verloren.
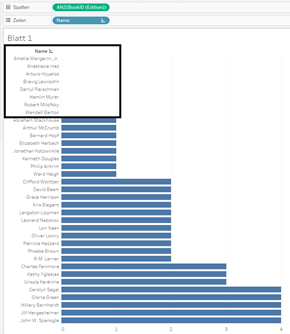
Dazu ein Beispiel: Ich möchte wissen, wie viele Bücher (Tabelle Book) ein bestimmter Autor (Tabelle Author) geschrieben hat. Um diese Frage mit Joins zu beantworten, muss ich vorab mit den Joins probieren und überlegen, wie ich zu dieser Antwort komme.
Das Vorgehen mit Relationships ist anders. Ich ziehe einfach die Namen der Autoren in die Zeile und die Anzahl der Bücher in die Spalte und habe sofort meine Antwort. Ich sehe sogar, welche Autoren keine Einträge haben. Genau das macht Relationships interessant, denn bei der Datenanalyse können Sie jetzt völlig anders vorgehen. Sie sehen jetzt schlichtweg mehr Informationen: Autoren, die keine Einträge haben. Diese Information geht nun nicht mehr verloren.

Relationship / Data Join / Data Blending
Hier ist eine Übersicht, die zeigt, welche Unterschiede es zwischen Relationship, Data Join und Data Blending gibt.

Extrakt
Bei der Datenextrahierung gibt es ebenfalls neue Optionen: Die logische und die physische Tabelle.
Option: Logische Tabelle
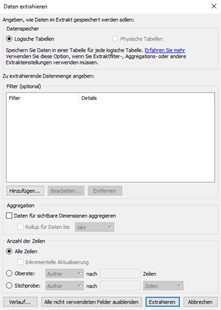
Nutzen Sie die logische Option, wenn die Datenmenge beim Extrakt reduziert werden soll. Dafür stehen Ihnen folgende Möglichkeiten zur Auswahl:
- Extrakt Filter
- Aggregationen
- Top N
- weitere Optionen
Ebenso sollten Sie diese Option nutzten, wenn Sie die Funktion RAWSQL nutzten.
Falls Sie sich unsicher sind, welche Option bei der Extrahierung der Daten zu nutzen ist, wählen Sie einfach immer diese Option.
Bei der Option „Logische Tabellen“ werden alle Tabellen aus der logischen Ebene extrahiert:
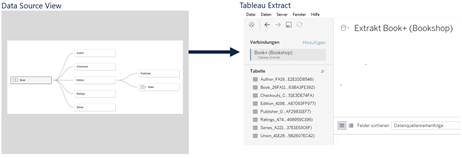
Option: Physische Tabelle
Nutzen Sie diese Option, wenn Ihre Tabelle folgende Voraussetzungen erfüllt:
- Alle Join Typen sind miteinander mit dem Zeichen „=“ verbunden
- Die Datentypen bei Relationships und Data Join sind identisch
- Es ist keine Benutzung von RAWSQL notwendig
- Keine inkrementelle Datenaktualisierung ist eingestellt bzw. notwendig
- Es sind keine Filter auf dem Datenextrakt notwendig
- Keine Top N oder Stichprobe sollen auf dem Datensatz angewandt werden
Es ist ebenso zu empfehlen, die Option Physische Tabelle zu nutzen, wenn Sie festgestellt haben, dass der Extrakt größer ist als er sein soll. Dieser Fall tritt ein, wenn die Anzahl aller Datensätze im Extrakt, den Sie mit der Option „Logische Tabelle“ erstellt haben, größer ist als die Anzahl der Datensätze bei der physischen Tabelle (Vor dem Extrakt).
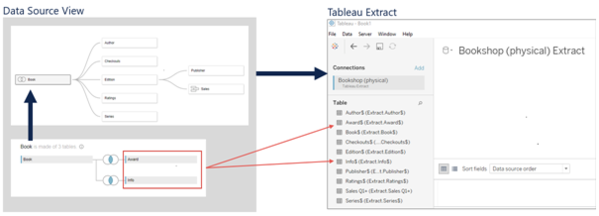
Bei der Option „Physische Tabellen“ werden alle Tabellen aus der logischen und physischen Ebene extrahiert
Sie haben Fragen zu Tableau oder grundsätzlich zum Thema Datenvisualisierung? Dann kommen Sie jederzeit gern auf uns zu.
Wir freuen uns auf den Austausch mit Ihnen!
Ihr M2 Team
+49 30 2089870 10
info@m2dot.com · M2@Facebook · M2@Twitter · M2@LinkedIn · M2@Instagram