

In einer kleinen Serie wird die Vorgehensweise in unseren Projekten entlang unserer Datenwertschöpfungskette geschildert. Die Artikelreihe besteht aus den drei Teilen „Datenzweck und Datenvisualisierung“, „Datentransformation und Datenanalyse“ sowie „Datensammlung“. zipcon consulting, eines der führenden Beratungsunternehmen in der Druck- und Medienbranche im deutschsprachigen Raum, hat uns gebeten, aus der Sicht von Datenexperten das Vorgehen für eine mittelständische Druckerei zu skizzieren.
Im ersten Teil dieser Reihe haben wir die Datenwertschöpfungskette definiert und die ersten Schritte auf dem Weg zur Datenvisualisierung und Datenanalyse beschrieben. Als Beispiel haben wir uns auf eine fiktive Druckerei mit 100 Mitarbeiter*innen fokussiert. Im zweiten Teil unserer Reihe ging es dann um die weiteren Schritte in der Datenwertschöpfungskette: Data Hub und Data Science.
Im dritten und letzten Teil der Serie, geht es um die Vorbereitung der Daten und Datenquellen für die letztliche Datenanalyse.
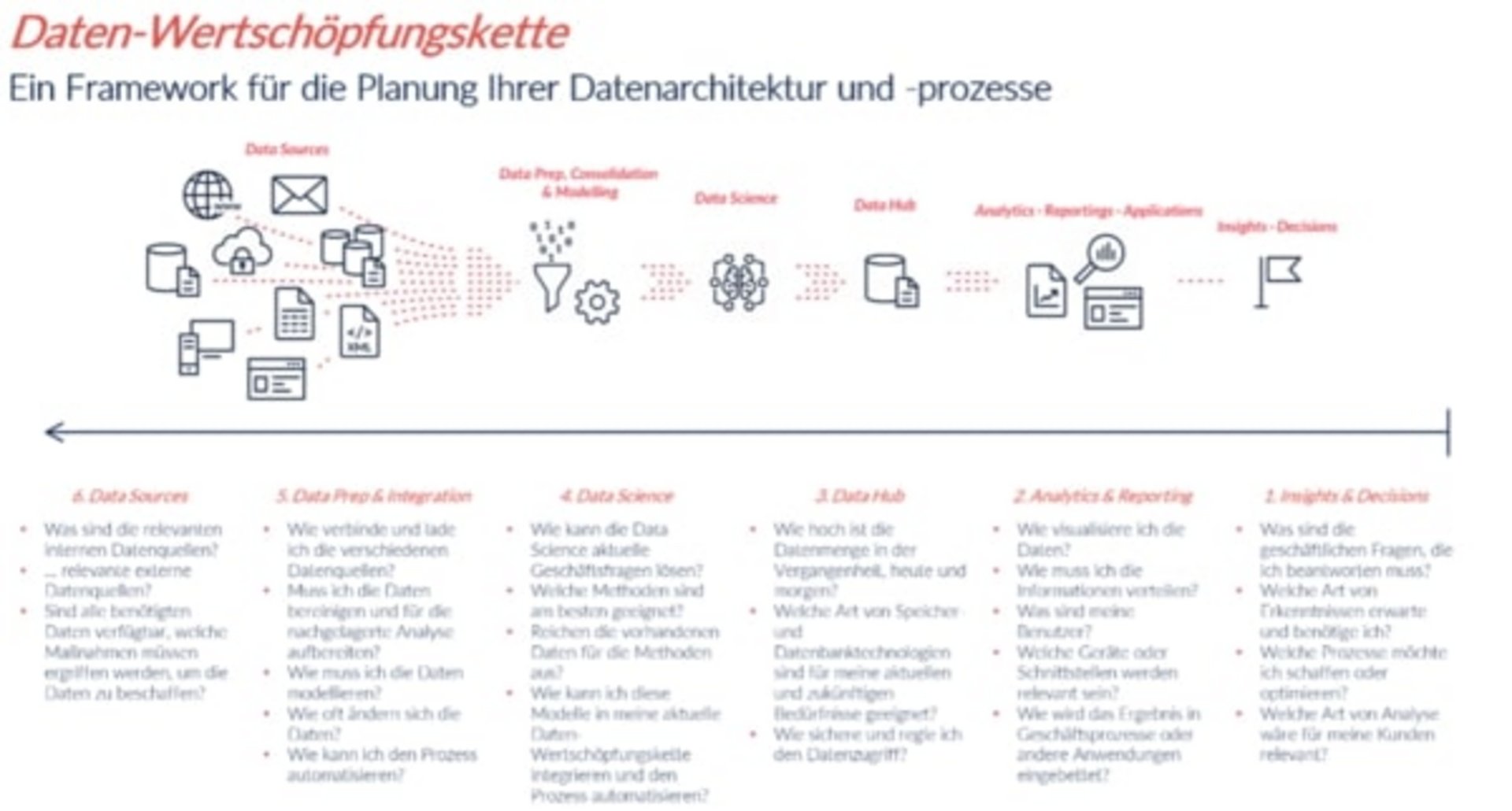
Data Prep & Integration
Wie verbinde und lade ich verschiedene Datenquellen?
Heutzutage bieten sämtliche BI-Tools eine Verbindung zu den gängigsten Datenbanken und können Dateien in unterschiedlichen Formaten auslesen.
In unserem Beispiel benötigen wir ganz bestimmte Daten aus der Datenbank: Stückzahl, Druckprodukte, Ort und Datum. Auf diese Daten können wir mit der MySQL Abfrage in der Datenbank zugreifen. Dafür gibt es zwei Möglichkeiten:
- Der Zugriff der Daten erfolgt direkt in der Datenbank. Im Anschluss können die Daten als csv. exportiert werden
- Der Zugriff auf die Datenbank erfolgt über Tableau. Die Daten werden direkt in Tableau zur Verfügung gestellt

In der Praxis können Daten aus unterschiedlichen Datenquellen zusammengeführt werden. Zum Beispiel können Ihre Daten in einer Excel-Datei auf ihrem Rechner und in einer Datenbank zur vorhanden sein. Nehmen wir an, um Ihre bestehenden Fragen zu beantworten, müssen beide Datenquellen miteinander verbunden werden.
Tableau Desktop bietet Ihnen diese Möglichkeit. In Tableau Desktop können Sie Daten aus unterschiedlichen Datenquellen miteinander verbinden.
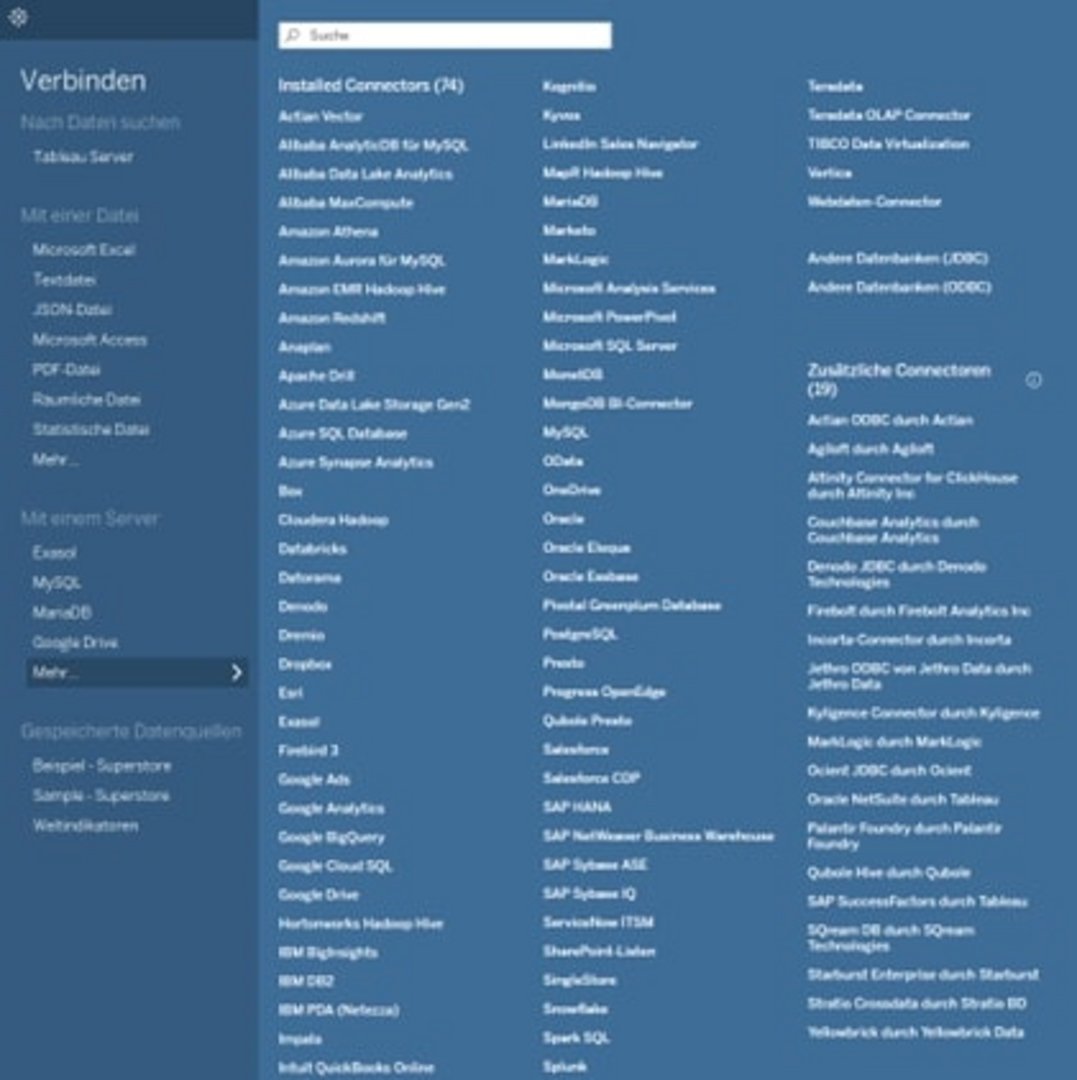
Beachten Sie dabei: wenn die Daten aus unterschiedlichen Datenquellen kommen, können Tabellen unterschiedliche Formate und Aggregationsebenen haben. Die Struktur der Daten und Datenquellen kann stark abweichen. Um Daten zu bereinigen und solche bestehenden Unterschiede zu synchronisieren, damit die Daten bestmöglich für die Datenanalyse präpariert sind, nutzen wir beispielsweise Tableau Prep.
Tableau Prep ist ein weiteres Tool im Tableau Portfolio.
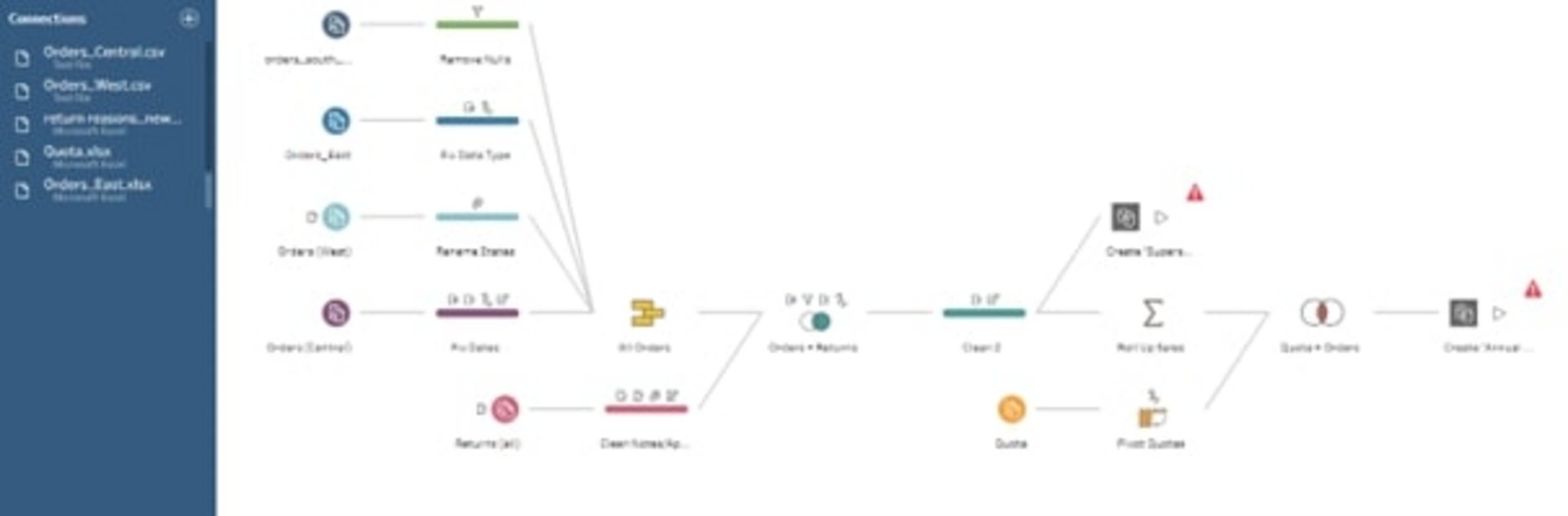
Dieses Tool bietet einfache und komfortable Möglichkeiten, ohne Programmierkenntnisse die Daten aus unterschiedlichen Datenquellen und Aggregationsebenen zusammenzuführen. Wie in Tableau Desktop gibt es auch bei Tableau Prep die Möglichkeit, die Verbindung zu Datenquellen herzustellen, unabhängig davon, ob sie lokal auf dem Rechner oder in einer Datenbank abgelegt sind.
Wie muss ich die Daten modellieren?
Daten können auf unterschiedliche Arten und Weisen modelliert werden. Man unterscheidet dabei folgende Optionen:
- Flaches Datenmodell: Eine zweidimensionale Matrix aus Datenelementen.
- Hierarchisches Modell: Daten werden in einer baumähnlichen Struktur gespeichert. Jeder Eintrag hat eine übergeordnete Einheit oder einen Stamm.
- Netzwerkmodell: Dieses Modell baut auf dem hierarchischen Modell auf. Es erlaubt 1:n-Beziehungen; deren Zuordnung erfolgt über eine Verknüpfungstabelle.
- Relationales Modell: Eine Prädikatsammlung über einen finiten Satz an Prädikatvariablen, für deren möglichen Werte oder Wertkombinationen Beschränkungen gelten.
- Sternschema-Modell: Normalisierte Fakten- und Dimensionstabellen entfernen Attribute mit niedriger Kardinalität für Datenaggregierungen.
- Data-Vault-Modell: Einträge mit langfristig gespeicherten, historischen Daten aus verschiedenen Datenquellen, die in Hub-, Satelliten- und Link-Tabellen angeordnet sind und darüber in Beziehung stehen.
Die Entscheidung zur Datenmodellierung wird von unterschiedlichen Faktoren beeinflusst. Wir müssen wissen, welche Datenbank wir nutzen. Und wir sollten uns darüber im Klaren sein, welche Visualisierung wir am Ende erstellen wollen.
Für unser Beispiel kommt das relationale Modell infrage, denn wir nutzen MySQL als Speicherort für unsere Daten. Bei diesem Modell werden die Daten thematisiert abgespeichert. Beispielsweise werden Autoren und Designer (Name des Autors, Adressen, Kategorisierung) in einer Tabelle gespeichert. Die Informationen zum Verlag werden in einer weiteren, separaten Tabelle gespeichert. Weitere Informationen können in zusätzlichen Tabellen angelegt werden. Auf diese Weise werden mehrere Tabellen nach einer bestimmten Thematik erstellt. Die Separierung der Informationen in unterschiedlichen Tabellen sorgt dafür, dass unsere Abfragen in der Datenbank schnell und performant durchgeführt werden. Die Tabellen sollten dafür eine Spalte mit einem eindeutigen Schlüssel beinhalten. Meistens sind das ID-Nummern. Anhand dieser Schlüsselspalten können wir Tabellen miteinander verbinden und uns eine individualisierte Tabelle bauen.
Die untere Abbildung zeigt ein solches Schema. Das Schema legt fest, welche Daten in der Datenbank gespeichert werden und wie diese Daten in Beziehung zueinander stehen. Der Vorgang zum Erstellen eines Schemas nennt sich dann Datenmodellierung.
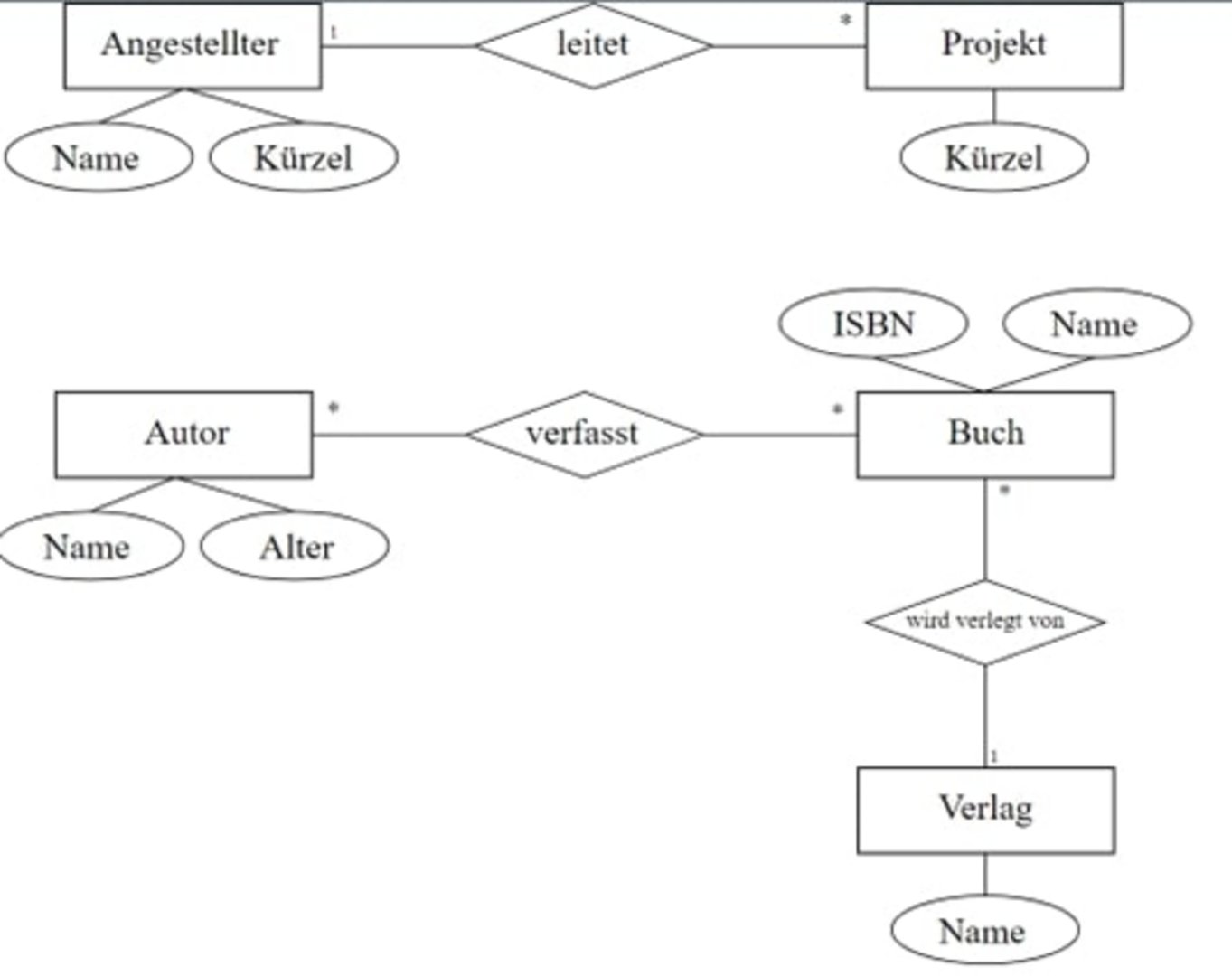
Datenquellen
Nun haben wir unsere Frage vom Anfang des Prozesses definiert und wissen, welche Daten benötigt werden. Unsere Ausgangsfrage war, in welcher Stückzahl Druckprodukte wie Broschüren, Flyer oder Postkarten in den vergangenen fünf Jahren (2016 - 2021) in Deutschland produziert wurden.
Zur Beantwortung der Fragen benötigen wir folgende Daten: Druckprodukte, Stückzahl, Ort und Datum
Liegen diese Information innerhalb des Unternehmens vor, muss geklärt werden, wie der Zugriff auf die Daten ermöglicht werden kann. Zu internen Unternehmensdaten können je nach Auswertungsanforderung natürlich auch extern verfügbare, öffentliche Daten hinzugefügt werden. Die benötigten Daten in unserem Beispiel sollten jedoch ausschließlich aus der interne Datenquelle kommen.
In einer Selfservice-Umgebung mit mehreren Publishern ist es nicht unüblich, dass ein Projekt in der Datenbank eine Vielzahl von Inhalten enthält, die ähnlich benannt sind oder auf gleichen bzw. ähnlichen, zugrunde liegenden Daten basieren. Zudem werden die Inhalte häufig ohne beschreibende Informationen veröffentlicht. So könnte ein Report beispielsweise unterschiedliche Benamungen haben:
- 20221003 Report_v1
- 20221004 Report_v1
- 20221004 Report_v2
- 20221004 Report_final
Der Grund für unterschiedliche Benennungen könnte etwa sein, dass in jeder Version minimale Änderungen vorgenommen wurden. Dies erschwert die Arbeit der Analysten, die aufgrund unklarer Dateinamen oder -historien kein Vertrauen in die Daten haben, die sie für ihre Analyse und Visualisierung verwenden sollen.
Um Ihren Benutzern zu helfen, die Daten zu finden, die für ihre Art der Analyse zuverlässig und empfohlen sind, sollte im Rahmen der Datenaufbereitung ein klarer und standardisierter Syntax- und Bereitstellungsprozess zugrunde liegen.
Viele Unternehmen haben ihren eigenen Kodex ausgearbeitet, wie sie die richtigen oder relevanten Datenquellen bezeichnen können. Beispielsweise könnte eine Datenquelle ein zertifiziertes Siegel haben oder nach einem Ampel-Schema benannt werden. Sobald dies gewährleistet ist, kann die Auswertung und Visualisierung der Daten mit Tableau begonnen werden.
Dies war der letzte Teil unserer Blogartikelreihe zum Thema Datenwertschöpfungskette. Wir hoffen, wir konnten Ihnen einen Überblick geben über unsere Vorgehensweise in einem klassischen Business-Intelligence-Projekt.
Sie haben Fragen zu diesem Artikel oder zu M2? Dann kommen Sie jederzeit gern auf uns zu. Wir freuen uns auf den Austausch mit Ihnen.
Ihr M2 Team
Telefon: +49 (0)30 20 89 87 010
info@m2dot.com · M2@Facebook · M2@Twitter · M2@LinkedIn · M2@Instagram
Ähnliche News

- OTC
- ThoughtSpot
- M2
- Alteryx
- Tableau
- Events
M2 NewsBlog: 14.02.2023
M2 Breakfast | Alter.Next | Customer Stories | Managed Services | OTC
Weiterlesen
- Webinar
- Training
- M2
- Tableau
M2 NewsBlog: 10.11.2022
Tableau Test Drive | Data Science Training | Mail Tool | M2 Team im neuen Look
Weiterlesen
- Exasol
- AWS
- Webinar
- Training
- M2
- Alteryx
- Tableau
M2 NewsBlog: 17.10.2022
Alteryx Classroom Training | Tableau like a Pro | Nosta Group | eCommerce Connector
Weiterlesen
- Exasol
- Webinar
- Training
- M2
- Tableau
M2 NewsBlog: 21.09.2022
13 Jahre M2 | Alteryx Inspire | Exasol & Labor Berlin | Videodreh | Zipcon
Weiterlesen


- Webinar
- Training
- M2
- Alteryx
- Events
- Tableau
M2 NewsBlog: 02.09.2022
M2 Events & News | Schulungen | Webinare | Tableau | Alteryx | AWS
Weiterlesen
- Webinar
- Training
- M2
- Alteryx
- Tableau
- Events
M2 NewsBlog: 19.08.2022
M2 Events & News | Schulungen | Webinare | Tableau | Alteryx | AWS
Weiterlesen

- M2
- Tableau
M2 - Ihr Partner für Datenvisualisierung und Analyse
Wir helfen Ihnen, das Datenpotential Ihres Unternehmens auszuschöpfen
Weiterlesen