

In einer kleinen Serie wird die Vorgehensweise in unseren Projekten entlang unserer Datenwertschöpfungskette geschildert. Die Artikelreihe besteht aus den drei Teilen „Datenzweck und Datenvisualisierung“, „Datentransformation und Datenanalyse“ sowie „Datensammlung“. zipcon consulting, eines der führenden Beratungsunternehmen in der Druck- und Medienbranche im deutschsprachigen Raum, hat uns gebeten, aus der Sicht von Datenexperten das Vorgehen für eine mittelständische Druckerei zu skizzieren.
Für die Steuerung eines Unternehmens auf der Basis von Daten liefern in vielen Druckereien die Finanzbuchhaltung und das ERP-System die Zahlen. Die Druckindustrie hat für die Key Performance Indikatoren (KPI) vielfach Standardberichte. Will man darüber hinaus und aus den Daten zusätzlichen Wert schöpfen, dann braucht es Experten für Datenvisualisierung und Analyse.
Am Anfang eines Datenprojekts steht häufig die Forderung nach mehr Transparenz bei Entscheidungen, die bisher vor allem auf Basis von Erfahrung und Intuition getroffen wurden. Ob es dabei um die Verarbeitung von Auflagedaten, das Monitoring von Druckprozessen oder die Analyse von Datenmengen und Ladeprozessen geht - die Prozessstruktur folgt einem wiederkehrenden Modell, für welches wir den Begriff Datenwertschöpfungskette (englisch: Data Value Chain) geprägt haben: Ein standardisiertes und bewährtes Framework für fast alle Projekte bei M2.
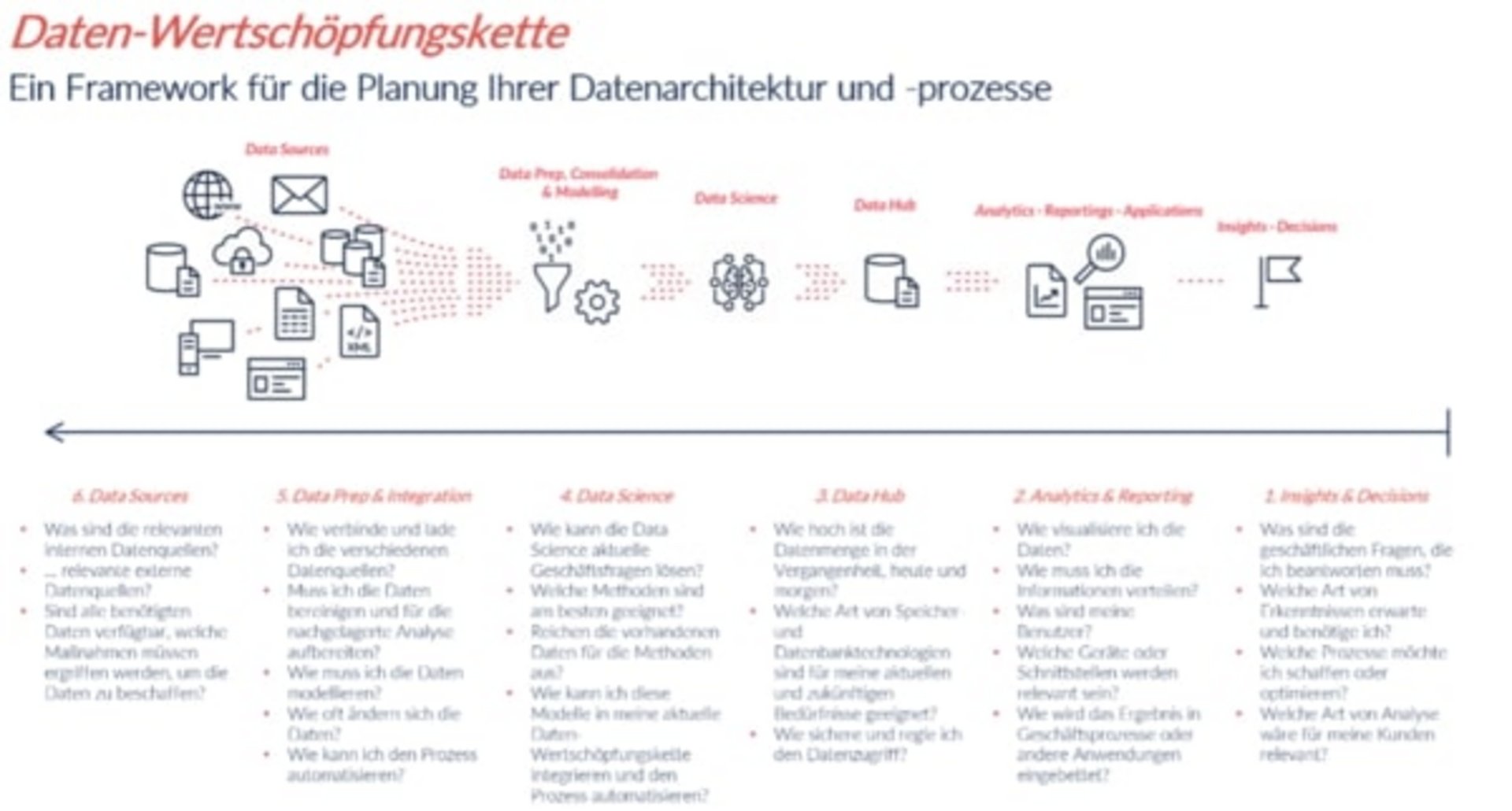
Die Daten-Wertschöpfungskette wird von rechts nach links gelesen. Entlang dieser Kette sind folgende Schritte definiert
-
Insights & Decisions
-
Analytics & Reporting
-
Data Hub
-
Data Science
-
Data Prep & Integration
-
Data Sources
Beim ersten Schritt geht es um folgende Fragen: welche Entscheidung soll getroffen werden? Welcher Prozess soll optimiert werden?
Im zweiten Schritt wollen wir herausfinden, welche Diagrammtypen diese Fragen beantworten können.
In Schritt drei, vier und fünf sollen wir rausfinden: Welches Datenmodell dieser Ansicht zugrunde liegt. Welche Datenmodellierungstechniken müssen angewendet werden?
Im letzten Schritt gehen wir auf die Frage ein, in welchen Systemen die Daten erhoben und welche Daten integriert werden müssen.
Auf der oben gezeigten Abbildung der Datenwertschöpfungskette sind die Fragen unter dem Diagramm aufgelistet, die in jeder Phase des Projekts gestellt werden. Die Antworten auf diese Fragen sind essenziell. Sie helfen uns dabei, die Aufgaben zu identifizieren und das Projekt zu planen.
Nachfolgend wird der Prozess der Datenwertschöpfungskette anhand einer fiktiven Druckerei XY mit 100 Mitarbeiterinnen und Mitarbeitern erläutert.
Insights & Decisions
Der Prozess in der Datenwertschöpfungskette beginnt mit den Business-Fragen. Beispielsweise: Wie viele Druckereien gibt es vor Ort, wie viele potenzielle Kunden gibt es, was wollen die Kunden erreichen, in welcher Menge wollen die Kunden ein Produkt erwerben, gehen die Kunden auf neue Trends ein – dieses Wissen ist Grundvoraussetzung für das Überleben der Druckerei.
Um unser Beispiel anhand der Datenwertschöpfungskette greifbar zu machen, nehmen wir folgendes Beispiel:
Unsere Druckerei möchte einen digitalen Bericht in Form eines interaktiven Dashboards erstellen. Das Dashboard wird für das Management des Unternehmens erstellt. Dabei möchte die Druckerei folgende Frage beantworten:
In welcher Stückzahl wurden Druckprodukte wie Broschüren, Flyer oder Postkarten in den vergangenen fünf Jahren (2016 - 2021) in Deutschland produziert?
Anhand dieser Information möchte die Druckerei herausfinden, wie stark hat die Pandemielage die Druckauflage beeinflusst.
Die Antworten auf diese Fragen sind letztlich für unterschiedliche Handelsszenarien relevant. Sie können signifikanten Einfluss auf Anpassungen der Produktionsprozesse oder der Planung von Arbeitsressourcen haben.
Bei der Analyse dieser Daten geht es nicht nur darum, die Antworten auf diese Fragen zu finden. Es geht auch darum, zu verstehen, welche Technologien bei welchem Schritt der Datenwertschöpfungskette das Unternehmen unterstützen könnten.
Analytics & Reporting
Wie visualisiert man die Daten?
Die Anzahl der Menge von Druckprodukten über die letzten fünf Jahre kann als Liniendiagramm dargestellt werden. Möchte ich wiederum Jahre miteinander vergleichen, so ist ein Säulendiagramm besser geeignet.
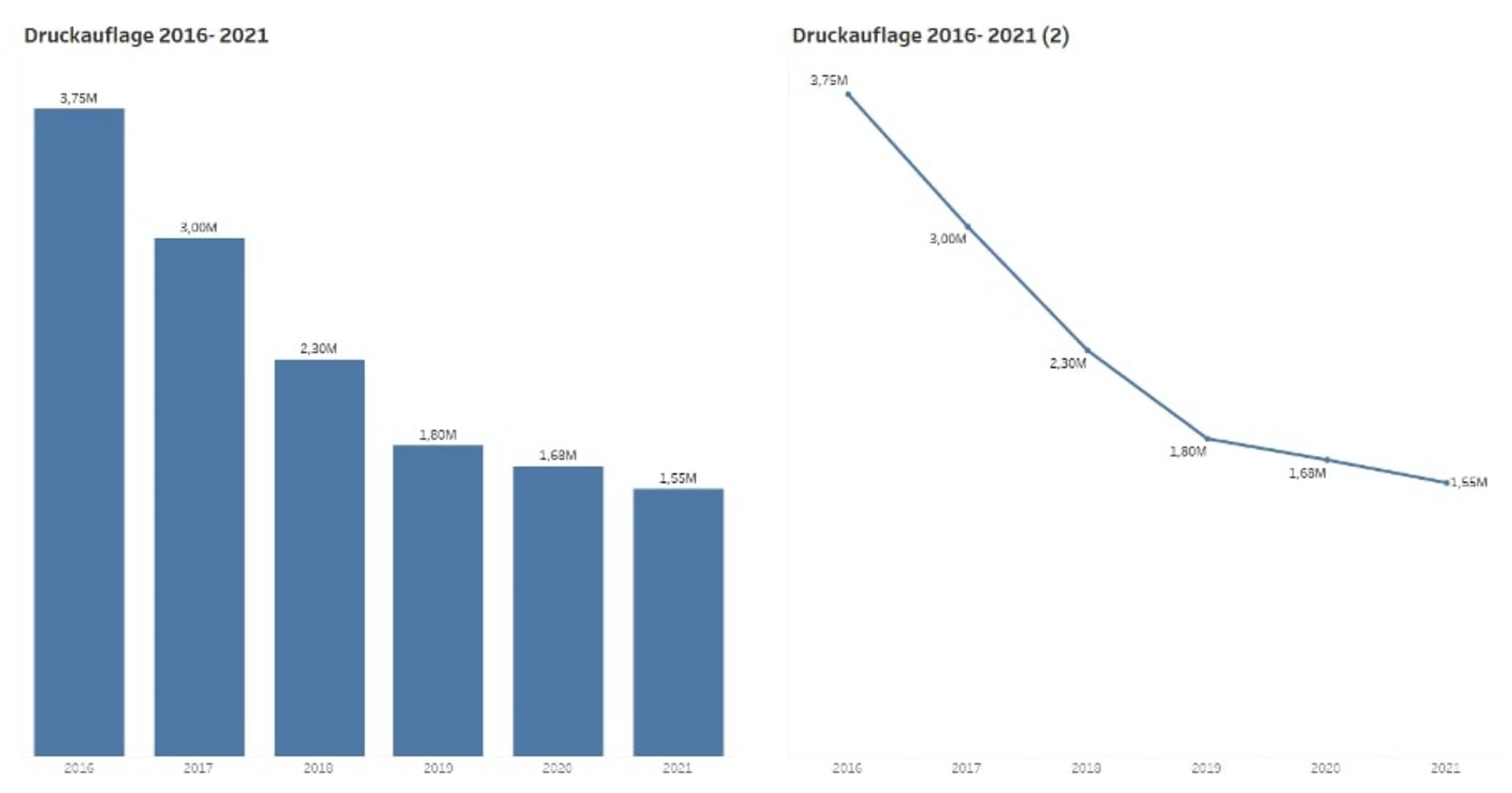
Das Wissen über Diagrammtypen ist hier essenziell. Die Fragestellung spielt dabei eine wichtige Rolle. Man muss die Botschaft exakt formulieren, um den richtigen Diagrammtyp auszuwählen.
Eine gute Ressource hierfür ist Visual Vocabulary von Financial Times https://ft-interactive.github.io/visual-vocabulary/
Das Visual Vocabulary ist eine große Hilfe bei der Diagrammwahl, wenn man sich mit dem Thema Datenvisualisierung wenig auskennt.
Wer sind die Nutzer?
Neben der Frage des Visualisierungstyps muss ich ebenso wissen, wer das Dashboard zukünftig konsumieren wird. In unserem Beispiel ist es das Management des Unternehmens. Die Information über unseren Nutzer und Endanwender ist ausgesprochen wichtig. Basierend darauf wird der Kontext im Dashboard erstellt. Hilfstexte und Erklärungen auf dem Dashboard sollten Kennzahlen und Definitionen beinhalten, die für die Zielgruppe relevant sind.
Hätten wir die Marketing-Abteilung als Zielgruppe, müssten wir mit Marketingkennzahlen arbeiten. Jede Abteilung schaut auf Informationen aus einem unterschiedlichen Blickwinkel. Obwohl es häufig um identische Zahlen geht, werden unterschiedliche Abteilungen die Zahlen sehr unterschiedlich interpretieren.

Welche Endgeräte sind relevant?
Wir bei M2 haben uns für Tableau Software entschieden. Tableau Software ist die führende Software für Datenvisualisierung, Daten Analyse und Datenmanagement.
Die Dashboards werden mit Tableau Desktop erstellt. Bei der Erstellung von Dashboards in allen ersten Schritt muss man auch den Zweck des Dashboards kennen. Ein Dashboard kann vielseitig genutzt werden:
- Interaktiv auf der Website
- Ausgedruckt, auf dem Papier
- Als Information in einer Präsentation
- Als eingebettete Version (das heißt,das Dashboard wird in einem Blogartikel auf einer Website veröffentlicht)
- Interaktiv auf dem Tablet
- Interaktiv auf dem Smartphone
Kennt man diese Informationen, sollte man dementsprechend die Größe des Dashboards bei der Erstellung wählen.
Tableau bietet die Möglichkeit, Dashboards intuitiv zu bauen und diese Ergebnisse mit Kollegen zu teilen.
Wer darf auf das Dashboard zugreifen?
Unternehmen verfügen heutzutage über eine große Anzahl von Daten, die oft sehr sensibel sind. Es gibt Daten, die wir nicht teilen dürfen oder nicht teilen wollen. Die Frage ist daher: Wer darf auf mein Dashboard zugreifen? Diese Frage sollte ganz am Anfang des Erstellungsprozesses gestellt werden.
In unserem Beispiel möchte die Druckerei XY die Kennzahlen der Auflage erst einmal nur auf der Management-Ebene bekannt machen. In diesem Fall soll das Dashboard also nur für bestimmte Personen im Unternehmen zugänglich sein.
Tableau Server bietet die Möglichkeit, solche Inhalte für bestimmte Gruppen zu teilen und Zugriffsberechtigungen entsprechend zu managen.
Wie sollen Daten analysiert werden?
Datenanalyse an sich ist ein umfangreiches Feld, welches viel Wissen und Erfahrung erfordert. Nicht umsonst existiert der Beruf des Data Analysten.
Für unser Beispiel werden wir diesen Schritt in der Datenwertschöpfungskette vereinfachen. In unserem Beispiel handelt es sich um eine Kennzahl: Die Druckauflage. Diese Kennzahl brauchen wir in der aggregierten Form für die Jahre 2016 – 2021.
Das Verständnis über Datenaggregation ist sehr wichtig. Im Alltag haben wir häufig mit aggregierten Zahlen zu tun, was dabei aber nicht jedem wirklich bewusst ist.
Datenaggregation ist eine Methode zur Datenerfassung und -zusammenfassung in einem Abrechnungsdatensatz, der ansonsten mit mehreren Datensätzen dargestellt wird. Daten können also auf unterschiedlichen Aggregationsstufen summiert und dargestellt werden.
Wenn wir die Kennzahl der Druckauflage für das Jahr 2021 betrachten, dann müssen wir wissen, wie sich diese Zahl zusammensetzt und welche Elemente addiert werden, damit wir in Summe die Stückzahl von 3,7 Millionen erhalten.
Das Beispiel unten zeigt, wie die Rohdaten auf unterschiedlichen Aggregationsstufen zusammenaddiert werden können.
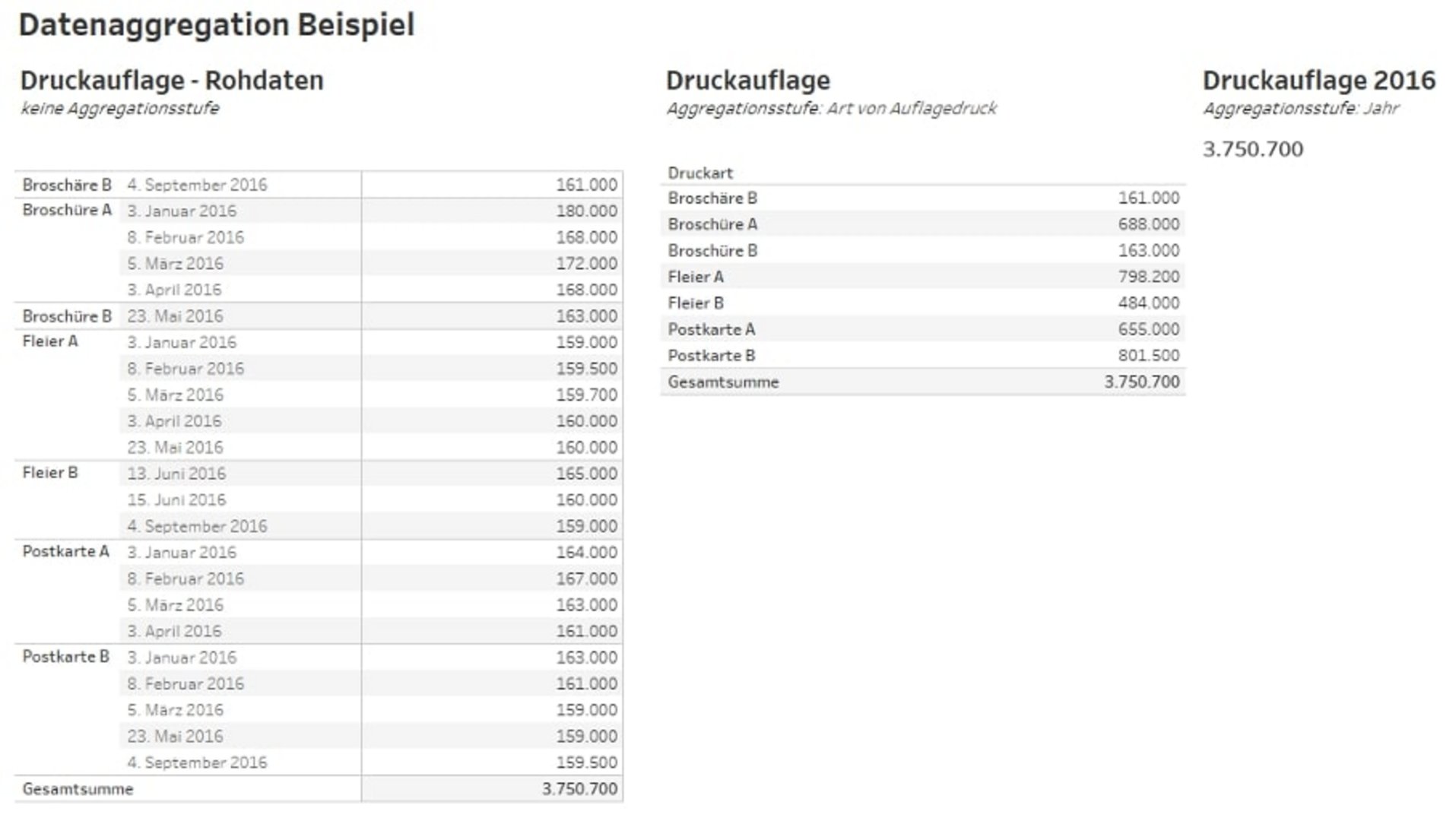
Die Datenaggregation kann in jeder Größe angewandt werden, von einfachen Tabellen bis hin zu Data Lakes. So können Informationen zusammengefasst und Schlussfolgerungen auf der Grundlage datenbasierter Erkenntnisse gezogen werden.
Bei Datenanalysen steht das Ziel im Vordergrund, interessante Trends und Muster in den Daten zu erkennen. Dabei spielen explorative Analysen und deskriptive Statistiken eine zentrale Rolle.
Bei der explorativen Datenanalyse geht es darum, die Daten zu erforschen, um deren Kontext zu verstehen. Bei diesem Schritt werden unterschiedliche Diagrammtypen erstellt, die nicht unbedingt an die Endanwender kommuniziert werden.
Deskriptive Statistik hilft, die Daten zu beschreiben. Messwerte wie Standardabweichung, arithmetische Mittel, Korrelationen oder lineare Regressionen helfen uns dabei, Daten richtig zu interpretieren und Zusammenhänge zu verstehen.
Wir sind am Ende vom zweiten Schritt angekommen: Analytics & Reporting. Im nächsten Blogartikel wird es dann um die Themen Data Hub und Data Science gehen.
Den zweiten Teil dieser Serie lesen Sie hier – erfahren Sie darin mehr zu den nächsten Schritten Data Hub und Data Science auf unserer Datenwertschöpfungskette.
Sie haben Fragen zu diesem Artikel oder zu M2? Dann kommen Sie jederzeit gern auf uns zu. Wir freuen uns auf den Austausch mit Ihnen.
Ihr M2 Team
Telefon: +49 (0)30 20 89 87 010
info@m2dot.com · M2@Facebook · M2@Twitter · M2@LinkedIn · M2@Instagram
Ähnliche News

- OTC
- ThoughtSpot
- M2
- Alteryx
- Tableau
- Events
M2 NewsBlog: 14.02.2023
M2 Breakfast | Alter.Next | Customer Stories | Managed Services | OTC
Weiterlesen
- Webinar
- Training
- M2
- Tableau
M2 NewsBlog: 10.11.2022
Tableau Test Drive | Data Science Training | Mail Tool | M2 Team im neuen Look
Weiterlesen
- Exasol
- AWS
- Webinar
- Training
- M2
- Alteryx
- Tableau
M2 NewsBlog: 17.10.2022
Alteryx Classroom Training | Tableau like a Pro | Nosta Group | eCommerce Connector
Weiterlesen
- Exasol
- Webinar
- Training
- M2
- Tableau
M2 NewsBlog: 21.09.2022
13 Jahre M2 | Alteryx Inspire | Exasol & Labor Berlin | Videodreh | Zipcon
Weiterlesen


- Webinar
- Training
- M2
- Alteryx
- Events
- Tableau
M2 NewsBlog: 02.09.2022
M2 Events & News | Schulungen | Webinare | Tableau | Alteryx | AWS
Weiterlesen
- Webinar
- Training
- M2
- Alteryx
- Tableau
- Events
M2 NewsBlog: 19.08.2022
M2 Events & News | Schulungen | Webinare | Tableau | Alteryx | AWS
Weiterlesen

- M2
- Tableau
M2 - Ihr Partner für Datenvisualisierung und Analyse
Wir helfen Ihnen, das Datenpotential Ihres Unternehmens auszuschöpfen
Weiterlesen