
- Technology
- AI
„Die Architektur folgt dem Workload. Nicht der Partnerschaft."
Die EU entscheidet über Souveränität – doch blockiert wird auf Use-Case-Ebene.
Weiterlesen
Einordnung und Entscheidung
Als die Europäische Kommission am 17. April einen Cloud-Rahmenvertrag über 180 Millionen Euro an vier europäisch geführte Anbieter- bzw. Konsortialgruppen vergab, war die mediale Deutung innerhalb von Stunden gesetzt: Die EU hat sich gegen die US-Hyperscaler entschieden. AWS, Microsoft und Google seien aus dem Rennen, Souveränität heiße ab jetzt: rein europäisch.
Die Pressemitteilung der Kommission selbst sagt etwas anderes. Sie hält ausdrücklich fest, dass außereuropäische Technologien unter Souveränitäts-Auflagen weiter zulässig sind. Zwischen der Schlagzeile und dem Dokument liegt ein Riss — und in diesem Riss passiert in deutschen Verwaltungen gerade das Gegenteil dessen, was Schlagzeilen vermuten lassen. Nicht schnelle Migration zu europäischen Anbietern, sondern Stillstand.
Wir führen dieses Gespräch aus zwei Gründen. Erstens, weil wir in den vergangenen Wochen in Public-Sector-Projekten beobachten, wie die verkürzte Deutung zur Entscheidungsverhinderung wird. Zweitens, weil wir als AWS Advanced Tier Partner in einer Position sind, in der Zurückhaltung einfacher wäre als Klarheit. Florian Rieger leitet bei M2 den Bereich Data & Analytics und verfügt über mehr als zehn Jahre Erfahrung in der Entwicklung von Cloud- und Datenarchitekturen für komplexe Datenlandschaften in Konzernen, Mittelstand und öffentlicher Verwaltung. Das Gespräch führte er am 20. April mit Robert Schneider, Marketing Lead bei M2.
Florian, die EU-Kommission vergibt 180 Millionen Euro an vier europäische Konsortien, und die Schlagzeilen schreiben von einer Absage an AWS und Microsoft. Was genau stimmt daran nicht?
Die Entscheidung selbst stimmt. Der Rahmenvertrag ist vergeben, die Konsortien sind benannt, das Volumen ist korrekt. Was nicht stimmt, ist die Verallgemeinerung. Dieser Vertrag gilt für die EU-Organe — für die Kommission selbst, ihre Agenturen, ihre Einrichtungen. Er ist keine Marktordnung für europäische Unternehmen und Verwaltungen. Und in der Pressemitteilung der Kommission steht ein Satz, den fast niemand zitiert hat: Außereuropäische Technologien können, wenn sie in einem strengen und angemessenen Rahmen betrieben werden, das erforderliche Mindestmaß an Souveränität erfüllen.¹
Wichtig ist auch, dass die Kommission nicht einfach „europäisch gegen nicht-europäisch" bewertet hat, sondern nach einem abgestuften Modell: den Sovereignty Effectiveness Assurance Levels, kurz SEAL. Zweck des Modells ist es, souveräne Cloud-Angebote für Vergabeverfahren einzuordnen, Mindestanforderungen zu definieren und Abhängigkeiten von Nicht-EU-Anbietern messbar zu machen. Die Skala reicht von SEAL-0 — faktisch keine Souveränität — bis SEAL-4, also vollständige europäische Kontrolle und Unabhängigkeit von Nicht-EU-Gesetzen.
Derzeit bewegen sich die meisten europäischen Anbieter im Bereich SEAL-2 bis SEAL-3, oft in Kooperation untereinander oder mit Nicht-EU-Technologie. Die luxemburgisch-französische Partnerschaft aus OVHcloud und CleverCloud, die französische Scaleway und der deutsche Anbieter STACKIT haben SEAL-3 erreicht. Das belgische Konsortium Proximus nutzt Google-Cloud-Services und erreicht SEAL-2. Weitere Kooperationen werden folgen, ebenso eigenständige europäische Entwicklungen. Parallel dazu bringen Microsoft und AWS eigene souveräne Angebote auf den Markt — die AWS European Sovereign Cloud und Microsoft Cloud for Sovereignty —, die in Europa betrieben werden und ebenfalls an den SEAL-Anforderungen gemessen werden.
Die EU setzt mit Vergabe und SEAL-Framework Maßstäbe für sensible Behördendaten. Das ist sinnvoll, wo das Schutzniveau es verlangt. Gleichzeitig macht das Modell selbst deutlich: Nicht jeder Workload braucht das höchste Level. Unkritische Anwendungen, Open-Data-Portale oder einfache Bürgerdienste kommen in der Regel ohne strenge Souveränitätsverpflichtungen aus — und genau hier bleiben etablierte Hyperscaler oft der wirtschaftlich überlegene Weg. Das ist die eigentliche europäische Linie, und sie ist keine Fußnote: Die Trennlinie verläuft nicht zwischen Europa und den USA, sondern zwischen Workloads, die echte Souveränität brauchen, und Workloads, bei denen sie keine Rolle spielt.
Warum setzt sich diese falsche Deutung der EU-Entscheidung so schnell durch?
Weil Souveränität ein emotionales Wort ist. Schlagzeilen sind kurz, Pressemitteilungen nicht. Das entscheidet über Reichweite. Und Entscheider im Stress suchen nach einem einfachen Kriterium. Geografie ist ein einfaches Kriterium — europäisch oder nicht. Governance-Architektur ist schwieriger — wer betreibt das Ding, wer hat Zugriff auf die Schlüssel, wer kann welche Daten unter welcher Rechtsordnung anfordern. Der zweite Punkt ist der, der zählt. Der erste wird jedoch gestellt, weil er schneller zu beantworten ist.
Kannst du den Unterschied technisch erklären — was genau macht ein Angebot „souverän“, das auf US-Technologie basiert?
Nimm AWS European Sovereign Cloud als Beispiel. Das ist keine weitere europäische Region der allgemeinen AWS Cloud, es ist eine separate Cloud-Partition. Betrieben über europäische beziehungsweise deutsche Rechtseinheiten, mit operativen Kontrollen, Support- und Betriebsmodellen innerhalb der EU sowie einer schrittweisen Umstellung auf ausschließlich EU-Bürger mit Sitz in der EU.² Das ist eine andere Konstruktion als eine Region in Frankfurt, Paris, Stockholm oder Irland, die von der US-Mutter administriert und global geführt wird.
Bei Delos, S3NS und Bleu sieht man Varianten desselben Grundmusters: Hyperscaler-Technologie wird über lokale, rechtlich und operativ abgesetzte Betriebsmodelle in souveränere Umgebungen überführt. Reifegrad und Zertifizierungsstand unterscheiden sich jedoch je Anbieter. S3NS hat die SecNumCloud-3.2-Qualifikation erhalten. Bleu zielt ebenfalls auf SecNumCloud 3.2. Delos ist ein anderes Modell für den deutschen Public Sector über eine SAP-Tochter.³
Das Muster ist in der Struktur überall gleich. Wer das nicht sieht, vergleicht Äpfel mit Birnen.
Wichtig ist dabei eine Ehrlichkeit in der Debatte. Echte Souveränität im Sinne vollständiger technologischer Unabhängigkeit von den USA oder China gibt es nicht. Zertifizierungsstellen, Identity-Provider, Entwicklungsplattformen wie GitHub, die meisten Open-Source-Libraries und die Hardware-Ebene selbst sind überwiegend außereuropäisch. Souveränität heißt in der Praxis nicht Isolation, sondern kontrollierte Abhängigkeit mit klaren Fall-Back-Ebenen.
Was beobachtest du gerade in euren Public-Sector-Projekten?
Das Gegenteil dessen, was die Schlagzeilen suggerieren. Statt beschleunigter Migration zu europäischen Anbietern sehen wir vor allem im Public Sector Stillstand. Die Entscheider trauen sich nicht. Sie stellen sich zwei Fragen, und beide führen nicht zu einer Antwort, sondern zu einer Pause: Darf ich überhaupt in die Cloud, oder zu AWS oder ist ESC wirklich souverän genug?
Diese Fragen sind nachvollziehbar, aber sie sind strategisch unproduktiv. Während Verwaltungen über sie nachdenken, laufen die Legacy-Systeme weiter, der Betriebsaufwand steigt, der Fachkräftemangel verschärft die Lage. Stillstand ist auch eine Entscheidung — nur eine, die niemand bewusst getroffen hat.
Im Commercial-Bereich ist das Muster anders. Dort kommt der Widerstand weniger vom Management als von der IT-Security. In den Projekten selbst, die wir begleiten, ist das kein großes Problem — wir finden Wege, die sowohl Security- als auch Business-Anforderungen tragen -die eigentliche Herausforderung liegt im Public Sector.
Was ist der Denkfehler hinter diesem Stillstand in den Verwaltungen?
Die Annahme, dass die Cloud pauschal alle Anforderungen erfüllen muss. Ein typisches Bild aus Public-Sector-Gesprächen: Die Entscheider denken die Cloud von der schärfsten denkbaren Anforderung aus. Also nicht nur Datenschutz und Security, sondern gleich Schutzniveau hoch und im Zweifel VS-NfD — Verschlusssache nur für den Dienstgebrauch. Mit dieser Brille geschaut ist jede Cloud-Option unzureichend. Und so wird sie beerdigt, bevor sie überhaupt bewertet wurde. Das ist die teuerste Form von Risikomanagement, die es gibt: aus Vorsicht gar nicht zu entscheiden.

Wie müsste eine Verwaltung ihre Cloud-Entscheidung stattdessen treffen?
Man müsste fragen: Was ist der reale Use Case? Auf der einen Seite stehen verwaltungsinterne Vorgänge mit sensiblen Personendaten oder Core-Themen wie Steuerverarbeitung und Personalakten. Auf der anderen Seite stehen Anwendungen mit niedrigem Schutzbedarf, trotz hoher Nutzung — etwa Open-Data mit interaktiven Infografiken oder die Anwendungen für Bürgerinformationen.
Diese Unterscheidung klingt banal, macht in der Praxis aber den Unterschied zwischen Jahren Stillstand und einer Architektur, die in Monaten produktiv geht. Ein Open-Data-Portal braucht keine VS-NfD-Infrastruktur. Eine Steuerverarbeitung braucht sie möglicherweise. Wer beides in derselben Souveränitäts-Kategorie bewertet, macht beides unbezahlbar — oder gar nicht.
Man muss den Trade-off benennen, der in der öffentlichen Debatte selten offen ausgesprochen wird: Mehr Souveränität heißt immer auch mehr Aufwand. Will man günstige, flexible und schlanke Lösungen und Prozesse, kommt man derzeit nicht an den Hyperscalern vorbei. Das ist keine Hyperscaler-Apologie. Das ist eine Aussage über den aktuellen Stand der europäischen Anbieterlandschaft, die sich entwickelt, aber in Service-Katalog, Skalierbarkeit und Time-to-Value den US-Anbietern noch nicht ebenbürtig ist. Wer das ignoriert, zahlt doppelt — einmal in Euro, einmal in verlorener Zeit.
Welche Rolle spielt KI in dieser Cloud-Entscheidung?
Die Cloud-Entscheidung ist mittlerweile immer eine KI-Entscheidung. Wer heute seine Cloud-Architektur festlegt, legt damit fest, wo seine Daten liegen, wer auf sie zugreifen kann, wie die Inferenz läuft, wie Modell-Trainings auditierbar sind. Sobald du beginnst, deine wichtigsten Daten für KI zu nutzen — Bürgerdaten, Verwaltungsvorgänge, Akten, Labor-Daten, Testdaten, was auch immer dein Kerngeschäft ist — wird die Cloud-Architektur zur KI-Architektur. Eine souveräne Cloud-Partition, in der die KI-Services fehlen oder nur eingeschränkt laufen, ist genauso ein Problem wie eine nicht-souveräne Cloud, in der deine sensiblen Daten für Modell-Training des Providers oder fremder Modelle verwendet werden.
Das verschiebt die Use-Case-Logik nachträglich. Ein Workload, der heute nach Sensitivität bewertet wird, kann in achtzehn Monaten in einer Kategorie landen, die er ohne KI nie erreicht hätte. Wer das nicht mitdenkt, trifft seine Cloud-Entscheidung auf veralteten Annahmen.
Gartner hat im April dazu Zahlen vorgelegt, die ich bemerkenswert finde. Unternehmen, die ihre KI-Initiativen als erfolgreich bewerten, investieren bis zu viermal mehr — gemessen am Umsatzanteil — in Datenfundamente und Governance als Unternehmen mit schwachen KI-Outcomes. Gleichzeitig sind nur 39 Prozent der Technologieverantwortlichen zuversichtlich, dass ihre aktuellen KI-Investitionen sich positiv auf die finanzielle Leistung auswirken werden.⁴
Was sagen dir diese Gartner-Zahlen zur KI-Zuversicht?
Sie zeigen vor allem strukturelle Unsicherheit: Viele Verantwortliche können den finanziellen Nutzen ihrer aktuellen KI-Investitionen noch nicht belastbar einschätzen. Und sie sagen, dass der Unterschied zwischen Erfolg und Misserfolg nicht in den Modellen liegt, sondern im Fundament. Gartner nennt das ContextLayer — die gouvernierte, semantisch angereicherte Datenbasis, auf der KI-Agenten überhaupt erst sinnvoll arbeiten können. Wir sehen in unseren Projekten immer wieder, dass zwar eine Menge Daten vorhanden sind und schnell in KI-Modellen nutzbar gemacht werden können, aber aufgrund fehlender, teils einfachster semantischer Informationen, Erklärungen und Definitionen keine verwendbaren Entscheidungen getroffen werden können. Es trifft jedoch nur die Hälfte des Problems.
Was fehlt?
Gartner behandelt Kontext als Daten-Thema. Das ist zu kurz gesprungen. Selbst ein perfekt gouvernierter Context Layer löst nicht die eigentliche Vertrauensfrage. Denn entscheidend ist nicht nur, welche Daten der KI-Agent sieht, sondern wie er auf ihrer Grundlage zu Antworten kommt — und ob sich diese Antworten nachvollziehen, reproduzieren und prüfen lassen.
Ein konkretes Beispiel: Du stellst einem Standard-KI-Agenten dieselbe Frage zu deinen Finanzzahlen an drei verschiedenen Tagen und bekommst drei unterschiedliche Antworten. Alle plausibel, alle numerisch eng beieinander, aber keine identisch. Der Kontext war in allen drei Fällen derselbe. Der Unterschied liegt in der Schicht darüber — in der Art, wie der Agent arbeitet. Für Compliance, für Finanzzahlen, für regulierte Entscheidungen ist das kein akzeptabler Zustand.
Untersuchungen zeigen, dass ungeerdete LLM-Ausgaben in offenen Fakten-, Recherche- und domänenspezifischen QA-Setups je nach Modell, Aufgabe und Benchmark relevante Fehler- beziehungsweise Halluzinationsraten im groben Bereich von zwanzig bis fünfzig Prozent erreichen können; in Hochrisiko-Domänen wie Recht oder Medizin liegen dokumentierte Werte teils darüber.⁵ Man muss sich vergegenwärtigen, was diese Größenordnung bedeutet, wenn die Ausgabe in einen Vorstandsbericht, in eine regulatorische Meldung oder in eine Kreditentscheidung einfließt.
Und wie löst man das?
Wir haben uns bei M2 in den letzten zwei Jahren intensiv mit dieser Schicht beschäftigt und sind zu der Überzeugung gekommen, dass es vier Prinzipien braucht, die über den Context Layer hinausgehen.
Erstens: Zahlen werden als ausführbarer Code berechnet, nicht vom Sprachmodell interpretiert. Ausführbarer Code macht Berechnungen reproduzierbar und prüfbar; er ersetzt aber nicht die Validierung von Logik, Datenbasis und Parametern.
Zweitens: Jede Aussage wird gegen eine deterministische Quelle geerdet — eine Datenbank, ein Dokument, ein Knowledge Graph. Was nicht geerdet werden kann, wird nicht beantwortet. Lieber keine Antwort als eine plausible, aber falsche.
Drittens: Die Validierung wird vom Erzeuger getrennt. Der Agent, der die Antwort produziert, prüft sie nicht selbst. Das macht ein anderer Agent, mit anderen Prüfkriterien. Das erhöht Redundanz, Prüftiefe und Fehlererkennung, ersetzt aber keinen deterministischen Prüfpfad.
Viertens: Jeder Schritt wird protokolliert. Was der Agent getan hat, ist im Nachhinein forensisch nachvollziehbar — nicht nur das Ergebnis, sondern der Weg dorthin. Das unterstützt Auditierbarkeit und Revisionsfähigkeit, ist aber auch zur Weiterentwicklung und Fehleranalyse sehr wertvoll.
Wir nennen diesen Ansatz Cognitive Architectures. Wenn du diese vier Prinzipien auf eine souveräne Cloud-Architektur anwendest, bekommst du etwas, das in regulierten Umgebungen tatsächlich trägt. Wenn du sie nicht anwendest, hast du eine schöne Datensammlung, aus der trotzdem jeder Agent macht, was er will.
Wir bei M2 sind AWS Advanced Tier Partner und seit kurzem auch STACKIT-Partner.
Wie glaubwürdig können wir bei diesem Thema anbieter-neutral beraten?
Die ehrliche Antwort: Unsere Glaubwürdigkeit entsteht nicht dadurch, dass wir keine Partner haben. Sie entsteht dadurch, dass wir transparent machen, welche Partner wir haben, und dass wir in Projekten dokumentieren, wann wir andere Lösungen empfehlen. Wir sind seit 2009 am Markt, wir haben weit über 200 Projekte umgesetzt, wir sind AWS Advanced Tier Partner, wir sind der erste Tableau-Partner in Deutschland, wir arbeiten mit Snowflake, Databricks, der T Cloud Public und STACKIT zusammen. Diese Breite ist kein Zufall und kein Vollständigkeits-Anspruch. Sie ist die Voraussetzung dafür, dass wir die Architektur dem Workload folgen lassen und nicht der Partnerschaft.
Wer nur einen Hammer hat, sieht überall Nägel. Wer drei Partner hat, kann auch mal sagen: Hier passt keiner von uns.
STACKIT haben wir bewusst aufgenommen — aufgrund der politischen Entwicklung, unseres bestehenden Netzwerks und des Potenzials, das wir bei europäischen Cloud-Anbietern sehen. Dabei sind wir offen: AWS ist Marktführer und in vielen Fällen der Anbieter der Wahl, wenn es darum geht, mit dedizierten, technologisch aktuellsten Services komplexe Lösungen zu bauen. Europäische Anbieter wie STACKIT entwickeln sich schnell, stehen im Managed-Service-Portfolio aber noch nicht auf dem gleichen Reifegrad wie die großen Hyperscaler — sind dafür bei bestimmten Architekturen und besonders sensiblen Workflows die passendere Wahl.
Dass diese Differenzierung nötig ist, zeigt schon die Kommunikation rund um die EU-Vergabe selbst. STACKIT hat den Zuschlag in einer Pressemitteilung als „endgültigen Beweis" für das Ende einseitiger Abhängigkeiten und als „finalen Beleg" für die Seriosität europäischer Lösungen bezeichnet. Das ist nachvollziehbare Kommunikation eines Anbieters, der gerade einen der wichtigsten europäischen Aufträge gewonnen hat — AWS, Microsoft oder die anderen drei Gewinner würden eine solche Entscheidung in ihren eigenen Pressemitteilungen nicht anders einordnen. Unsere Aufgabe als Beratung ist nicht, Pressemitteilungen zu kommentieren, sondern sie im Kundengespräch in den Gesamtkontext zu stellen — besonders dann, wenn sie von einem eigenen Partner kommen. STACKIT ist in bestimmten Architekturen der richtige Partner. In anderen nicht. Das gilt für jeden der vier Gewinner und für jeden Hyperscaler.
Deshalb ist unsere Empfehlung im Projektalltag immer anforderungsgetrieben, nicht partnergetrieben. Wenn ein Kunde fragt, ob AWS die richtige Plattform ist, beantworten wir das anhand seiner Architektur, seiner Regulierung und seines Betriebsmodells — und wenn eine andere Cloud, ein europäischer Anbieter oder schlicht On-Premise besser passt, empfehlen wir genau das. Dass wir Partner von AWS und STACKIT sind, ist dafür kein Konflikt, sondern Voraussetzung. Nur wer mehrere Optionen kennt und baut, kann glaubwürdig sagen, welche zum konkreten Workload gehört.
Was ist dein konkreter Ratschlag an einen Verwaltungsleiter oder CDO, der diese Woche liest, was die EU beschlossen hat?
Nicht in Panik ein neues Projekt aufsetzen. Aber auch nicht abwarten. Stattdessen eine halbtägige Workload-Bewertung machen. Setz dich mit deiner IT-Führung zusammen und gehe deine Use Cases durch — idealerweise nicht alle, sondern die kritischen fünfzig bis einhundert. Für jeden Use Case beantwortest du drei Fragen: Welche Daten liegen hier und welche Schutzbedarfsstufe greift wirklich? Welche Regulierung greift? Wer darf im Zweifelsfall zugreifen?
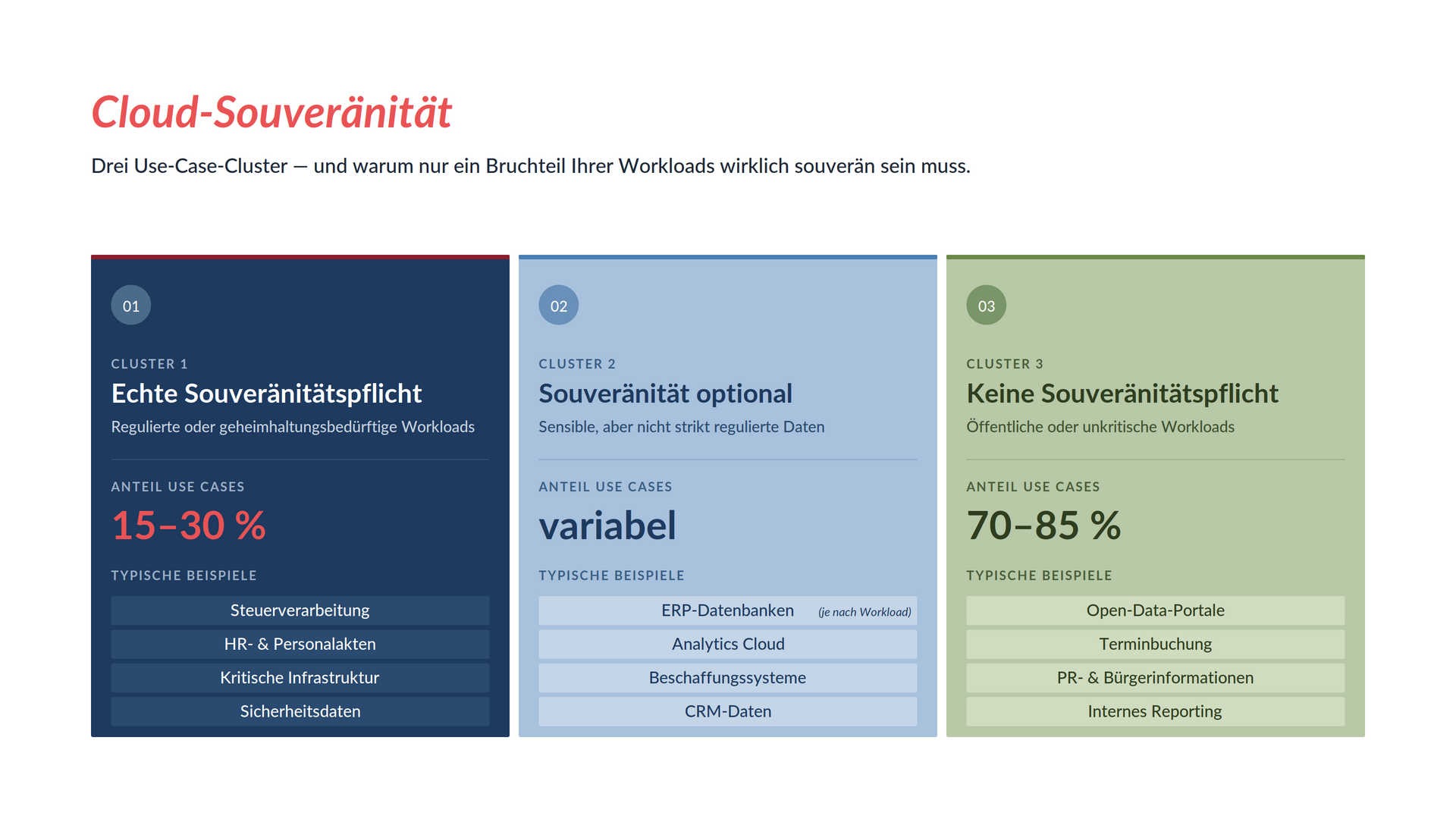
Am Ende des halben Tages hast du eine Matrix, in der sich drei Cluster abzeichnen: Use Cases, die echte Souveränitäts-Anforderungen haben — im Public Sector oft die mit VS-NfD-relevanten Daten oder kritischer Verwaltungsinfrastruktur. Use Cases, bei denen Souveränität optional ist. Und Use Cases, bei denen sie keine Rolle spielt — etwa Open-Data-Portale oder Bürgerinformations-Anwendungen.
In unserer Projekterfahrung liegen häufig nur fünfzehn bis dreißig Prozent der Use Cases in der ersten Kategorie. Das ist eine wichtige Information, weil sie die Dimension der Aufgabe klärt. Du musst nicht deine gesamte IT souveränisieren. Du musst wissen, welcher Teil wie souverän sein muss, und für diesen Teil eine Architektur bauen, die Reversibilität mitdenkt.
Warum ist Reversibilität als Architektur-Prinzip so wichtig?
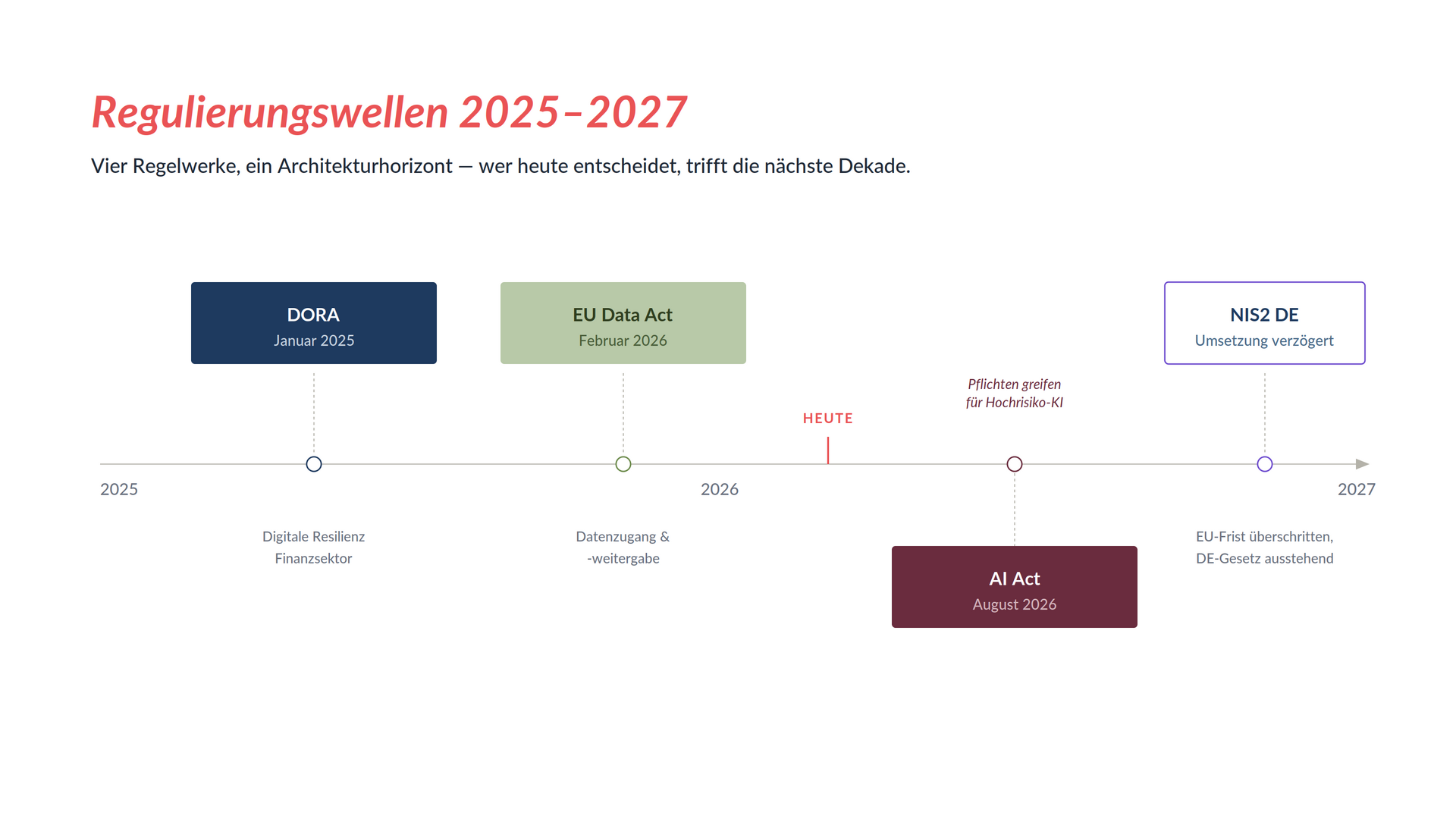
Weil die regulatorischen Anforderungen sich weiterentwickeln. DORA ist seit dem 17. Januar 2025 anwendbar, der EU Data Act seit dem 12. September 2025. NIS2 ist in Deutschland seit dem 6. Dezember 2025 umgesetzt. Beim AI Act greifen zentrale Hochrisiko-Pflichten nach aktueller Rechtslage ab August 2026 beziehungsweise August 2027; im Digital-Omnibus-Verfahren werden jedoch Verschiebungen diskutiert.
Jede dieser Regulierungen kann Anforderungen verschärfen. Wer heute eine Architektur baut, die sich in fünf Jahren nur noch mit massivem Aufwand anpassen lässt, hat ein strukturelles Problem. Wer von Anfang an austauschbare Komponenten, portable Datenschichten und klare Exit-Pfade einplant, zahlt in der Einrichtung mehr und im Lebenszyklus weniger. Das ist keine hypothetische Rechnung. Das ist die Lehre aus dem letzten Jahrzehnt Cloud-Migration.
Ein Satz, der in zwölf Monaten noch stimmen wird?
Souveränität ist eine Architektur- und Prozess-Entscheidung mit jahrelanger Wirkung.
Wer sie vertagt, trifft sie trotzdem — nur schlechter.
Vielen Dank für das Gespräch. Die Richtung ist absehbar – jetzt liegt die Chance darin, früh zu handeln und die eigenen Spielräume gezielt zu nutzen.
Warum jetzt der richtige Zeitpunkt ist zu entscheiden
Dieses Interview ist in den Tagen nach dem 17. April entstanden – in einer Phase, in der sich die Richtung bereits abzeichnet, viele Entscheidungen aber noch offen sind. Die Entwicklung ist klar: Regulatorische Anforderungen werden verbindlicher, souveräne Cloud-Angebote reifen, und KI wird zur bestimmenden Dimension jeder Cloud-Architektur. Die entscheidenden Weichen werden jetzt gestellt – nicht später.
Wer heute strukturiert entscheidet, schafft sich Spielraum. Wer wartet, entscheidet unter Druck. Wenn Sie Ihre Workloads klar einordnen möchten, laden wir Sie zu einem kurzen Austausch ein: 30–45 Minuten, konkrete Use Cases, klare Einschätzung. Ohne Produktverkauf – mit dem Ziel, fundiert zu entscheiden, welche Souveränitätsanforderungen für Ihre Workloads tatsächlich relevant sind.
Florian Rieger ist Practice Lead Data & Analytics bei M2 und seit über zehn Jahren im Unternehmen. Zuvor war er als Business Analyst bei Siemens tätig. Seine Überzeugung: Architekturentscheidungen mit jahrelanger Wirkung dürfen nicht aus Schlagzeilen heraus getroffen werden. Er berät konsequent vom Use Case her – und versteht Partnerschaften als Grundlage ehrlicher Beratung, nicht als deren Grenze.
M2 entwickelt seit 2009 Datenarchitekturen, die belastbare Entscheidungen ermöglichen – für über zweihundert Kunden, von DAX-Konzernen bis zur öffentlichen Verwaltung. Die nächste Stufe sind Cognitive Architectures: KI-Systeme, die auditierbar, reproduzierbar und anbieterunabhängig arbeiten. Keine Blackbox, sondern Architektur, die nachvollziehbar ist und Vertrauen schafft.
Viele Diskussionen zur souveränen Cloud scheitern an unscharfen Begriffen.
Entscheidend ist die klare Trennung zentraler Konzepte:
Ein Workload beschreibt den konkreten Anwendungsfall – etwa Steuerdaten oder Open Data – und definiert die tatsächlichen Anforderungen an Sicherheit und Souveränität.
Datenresidenz meint den physischen Speicherort von Daten. Relevant, aber für sich genommen kein ausreichendes Kriterium. Entscheidend ist die darüberliegende Kontrolle.
Diese wird als Datenhoheit (Data Sovereignty) beschrieben: Wer darf auf Daten zugreifen – und unter welcher Rechtsordnung?
Das Betriebsmodell bestimmt, wer eine Cloud betreibt und kontrolliert. Es ist einer der zentralen Hebel für echte Souveränität.
Dem gegenüber stehen Hyperscaler wie Amazon Web Services, Microsoft oder Google – leistungsfähig, aber nicht per se souverän.
Modelle wie die Sovereign Cloud Partition versuchen, diese Lücke zu schließen, indem sie Betrieb und Kontrolle in eine definierte Rechtszone verlagern.
Mit SecNumCloud existiert ein Beispiel für regulatorische Anforderungen, die genau diese Trennung absichern.
Unabhängig vom Anbieter bleibt Zugriffskontrolle zentral: Sie regelt, wer wann und unter welchen Bedingungen Zugriff erhält.
Vor dem Hintergrund wachsender Regulierung wird Reversibilität entscheidend – die Fähigkeit, Architekturen ohne Lock-in anzupassen oder zu wechseln.
Mit KI kommt eine weitere Ebene hinzu: Cognitive Architectures - so beschreiben wir Systeme, die nachvollziehbare, reproduzierbare Entscheidungen ermöglichen – statt Blackbox-Verhalten.
Quellen
¹ Europäische Kommission, Kommission vergibt Ausschreibung über 180 Mio. EUR für souveräne Cloud an vier europäische Anbieter, Pressemitteilung, 2026
² Amazon Web Services, AWS European Sovereign Cloud, Produktdokumentation, 2026
³ Microsoft; SAP; Delos Cloud; S3NS; Bleu, Cloud-Sovereignty-Angebote und Betriebsmodelle (Microsoft Cloud for Sovereignty, Delos Cloud, S3NS, Bleu), Produkt- und Unternehmensinformationen, 2026
⁴ Gartner, Organizations with Successful AI Initiatives Invest Up to Four Times More in Data and Analytics Foundations, Pressemitteilung, 2026
⁵ Dahl et al., Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models, Journal of Legal Analysis, 2024; Magesh et al., Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools, Journal of Empirical Legal Studies, 2025; Omar et al., Evaluating the Reliability of Large Language Models in Medical Applications, Communications Medicine, 2025
Die EU entscheidet über Souveränität – doch blockiert wird auf Use-Case-Ebene.
Weiterlesen
Eine Auszeichnung, die man sich nicht kaufen kann.
Weiterlesen
KI braucht Systeme, nicht nur schlaue Chatbots
Weiterlesen
Sicherheit, Souveränität und die Verantwortung der Organisationen
Weiterlesen

So wird Ihre Cloud-Migration zukunftssicher
Weiterlesen
Fortschritt für datengetriebene Innovation
Weiterlesen
Vorteile und Migrationsmöglichkeiten mit M2
Weiterlesen
So migrieren Sie Ihre Daten aus verschiedenen Systemen in Tableau Cloud
Weiterlesen